Amazon Connect now provides built-in capabilities for customer authentication within chats, making it easier to verify customer identity and deliver personalized experiences. You can use the new Authenticate Customer flow block to simplify authentication in your chat workflows. For example, unauthenticated customers who require agent assistance can be shown a pop-up to sign-in before connecting with an agent, allowing agent’s to provide more personalized and efficient support.
To get started, visit the new ‘Customer authentication’ page within the AWS Console to configure your identify provider, then add the Authenticate Customer block to your contact flow. To learn more, please refer to the help documentation or visit the Amazon Connect website. This feature is available in all commercial AWS regions where Amazon Connect is available.
You can now remove queues and routing profiles that are no longer required in your contact center directly from the Amazon Connect admin website, in addition to the API-based deletion that was previously supported. For example, if your team set up sample queues to test a use case that are no longer needed, or you are consolidating your routing profiles because you have reorganized agents, you can now click to remove the unwanted resources.
To get started, open the Amazon Connect admin website and navigate to the queues or routing profile page. Use the delete action to remove unneeded rows and free up service quotas for that resource. The updated UIs are available in all AWS Regions where Amazon Connect is offered. For more information, see the administrator guide. To learn more about Amazon Connect, the AWS contact center as a service solution on the cloud, please visit the Amazon Connect website.
Amazon Relational Database Service (Amazon RDS) for MariaDB now supports MariaDB minor versions 11.4.4, 10.11.10, 10.6.20, and 10.5.27. We recommend that you upgrade to the latest minor versions to fix known security vulnerabilities in prior versions of MariaDB, and to benefit from the bug fixes, performance improvements, and new functionality added by the MariaDB community.
You can leverage automatic minor version upgrades to automatically upgrade your databases to more recent minor versions during scheduled maintenance windows. You can also leverage Amazon RDS Managed Blue/Green deployments for safer, simpler, and faster updates to your MariaDB instances. Learn more about upgrading your database instances, including automatic minor version upgrades and Blue/Green Deployments, in the Amazon RDS User Guide.
Amazon RDS for MariaDB makes it straightforward to set up, operate, and scale MariaDB deployments in the cloud. Learn more about pricing details and regional availability at Amazon RDS for MariaDB. Create or update a fully managed Amazon RDS database in the Amazon RDS Management Console.
Amazon QuickSight is excited to announce the launch of Unique Key for Dataset, enabling users to define additional aspects of their data semantics. The unique key will be used to improve performance for QuickSight visuals, especially un-aggregated table charts. Previously, to maintain table pagination stability, all columns in the table visual were sorted, which was an expensive query causing performance latency. Now, with the unique key defined in the dataset, once the column is used in the visual, users will automatically experience improved sorting performance without compromising user behavior. For some cases, the new approach can increase the performance up to 60% decrease of the visual rendering time. For further details, visit here.
The new Unique Key for Dataset feature is now available in Amazon QuickSight Enterprise Editions in all QuickSight regions – US East (N. Virginia and Ohio), US West (Oregon), Canada, Sao Paulo, Europe (Frankfurt, Stockholm, Paris, Ireland and London), Asia Pacific (Mumbai, Seoul, Singapore, Sydney and Tokyo), and the AWS GovCloud (US-West) Region.
Amazon Q Business is now SOC (System and Organization Controls) eligible. Amazon Q Business is a generative AI–powered assistant that can answer questions, provide summaries, generate content, and securely complete tasks based on data and information in your enterprise systems.
With the Amazon Q Business SOC certification, customers, can now use Amazon Q Business for use cases that are subject to Service Organization Control (SOC) requirements. Amazon Q Business is now SOC 1, 2 and 3 compliant, allowing you to get deep insight into the security processes and controls that protect customer data. AWS maintains SOC compliance through extensive third-party audits of AWS controls. These audits ensure that the appropriate safeguards and procedures are in place to protect against security risks that may affect the confidentiality, integrity, and availability of customer and company data.
Amazon Q Business is SOC compliant in all of the AWS Regions where Amazon Q Business is supported. See the AWS Regional Services List for the most up-to-date availability information. To learn more about SOC eligible services, visit the webpage. To get started with Amazon Q Business, visit the product page to learn more.
Amazon WorkSpaces Personal now integrates with AWS Global Accelerator (AGA) to enhance WorkSpaces connection performance by optimizing streaming traffic through the AWS Global Network and edge locations. This feature particularly benefits customers whose end users connect to WorkSpaces across long distances.
The AGA feature can be enabled at either the WorkSpaces directory level or for individual WorkSpaces running DCV protocol. When advantageous, the service automatically routes the streaming traffic through the nearest AWS edge location and across AWS’s congestion-free, redundant global network, delivering a more responsive and stable streaming experience. The WorkSpaces service fully manages AGA usage, subject to outbound data volume limits detailed in WorkSpaces documentation.
This enhancement is available at no additional cost for Personal WorkSpaces running DCV protocol in all AWS Regions where Amazon WorkSpaces is supported, except Africa (Cape Town), Israel (Tel Aviv), AWS GovCloud (US), and China Regions.
Customers can configure this feature through the AWS Management Console, AWS Command Line Interface (CLI), or Amazon WorkSpaces APIs. For detailed configuration instructions and best practices, please refer to the Amazon WorkSpaces documentation.
Amazon RDS for Db2 now enables the creation of multiple Db2 databases within a database instance. This enhanced capability offers greater flexibility in managing databases and optimizing licenses for various enterprise workloads.
Customers can now provision and manage up to 50 Db2 databases within a single RDS for Db2 instance, eliminating the need to deploy and license databases individually for each RDS instance. Customers using multiple databases can quickly create, activate, deactivate or drop databases, enabling them to reduce the overhead of managing separate RDS for Db2 instances. To create multiple databases within an Amazon RDS for Db2 instance, simply set up an RDS instance in the AWS Management Console or using the AWS CLI, then use the create_database stored procedure to create multiple Db2 databases on that RDS instance.
Amazon RDS makes it simple to set up, operate, and scale Db2 deployments in the cloud. To learn more about Amazon RDS for Db2, check Amazon RDS for Db2 User Guide and Amazon RDS for Db2 pricing page for pricing details and regional availability.
Google Cloud’s Database Center provides a unified fleet management solution to help manage your databases at scale. In October 2024, Database Center was made available to all Google Cloud customers, with support for Cloud SQL, AlloyDB and Spanner engines.
Today we are expanding Database Center’s capabilities with the addition of Bigtable, Memorystore, and Firestore databases in preview. You now have a single, unified view where you can:
Gain a comprehensive view of your entire database fleet across all Google Cloud managed databases. No more silos of information or hunting through bespoke tools and spreadsheets.
Proactively de-risk your database fleet with intelligent and actionable availability and data protection recommendations for Bigtable and Firestore databases.
Optimize your database fleet with AI-powered assistance using a natural language interface to answer questions about all your Google Cloud databases,and quickly resolve fleet issues through optimized recommendations.
Let’s take a deeper look at the new Database Center capabilities for Bigtable, Memorystore and FIrestore.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud databases’), (‘body’, <wagtail.rich_text.RichText object at 0x3e22bcecdb50>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/products?#databases’), (‘image’, None)])]>
Gain a comprehensive view of your database fleet
Database Center simplifies database management with a single, unified view of all your Google Cloud managed database services, including Bigtable, Memorystore and Firestore. You can monitor these database resources across your entire organization, spanning multiple engines, versions, regions, projects, and environments or applications using labels. Specifically, Database Center now lets you:
Identify out-of-date database versions to ensure proper support and reliability
Track version upgrades, e.g., if Memorystore Redis 6.x to Memorystore Redis 7.0/ 7.2is updating at an expected pace
Ensure database resources are appropriately distributed, e.g., identify the number of Bigtable, Firestore, Memorystore databases powering the critical production applications vs. non-critical dev/test environments
Detecting and troubleshooting diverse database issues across the entire fleet.
Proactively de-risk your database fleet with intelligent recommendations
We’ve expanded Database Center’s proactive monitoring and issue-resolution capabilities to support Bigtable and Firestore, helping to ensure optimal availability and data protection for your existing database fleet. For instance, Database Center:
Proactively monitors Bigtable instances, detecting and helping to resolve failover gaps to minimize downtime and prevent service disruption
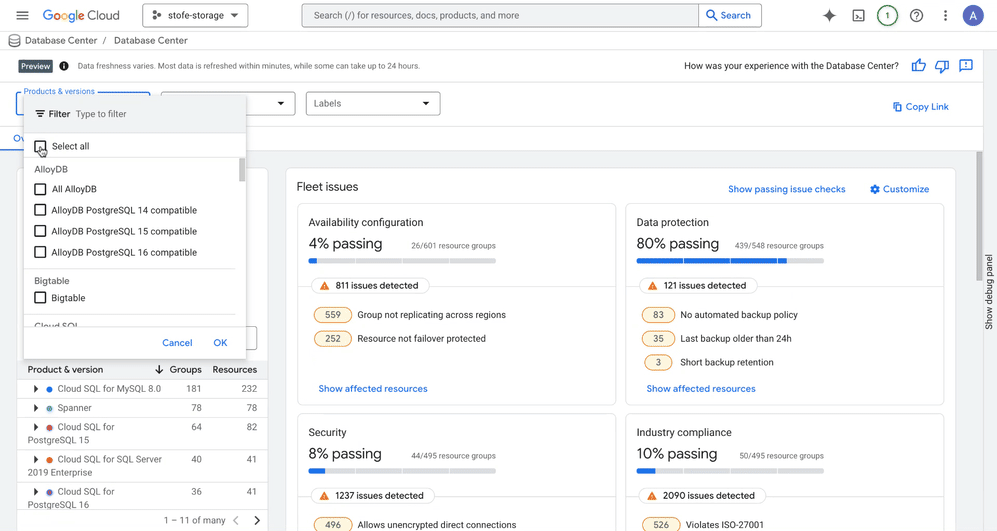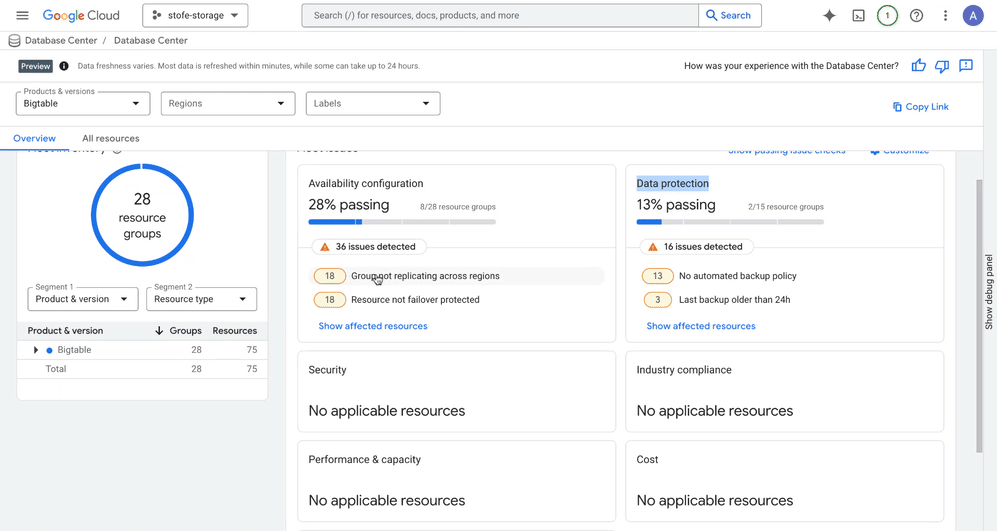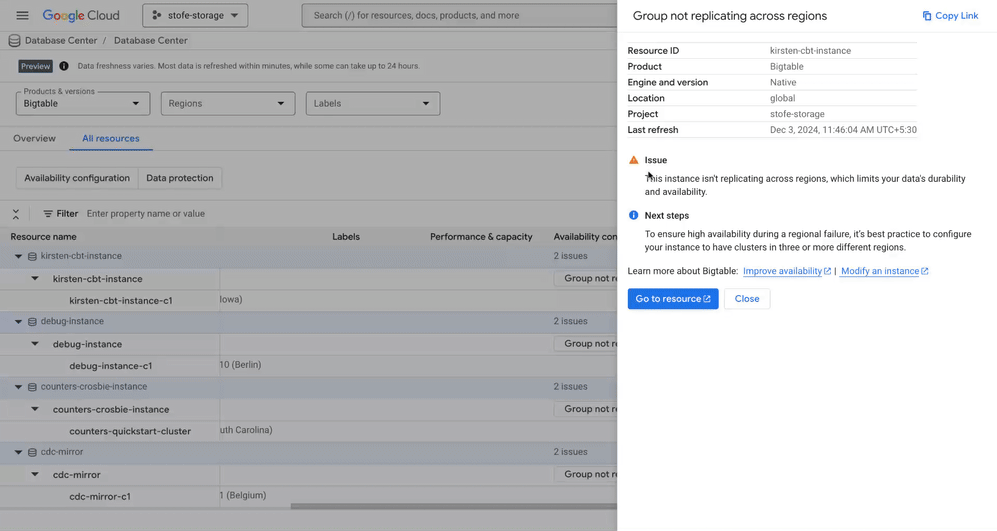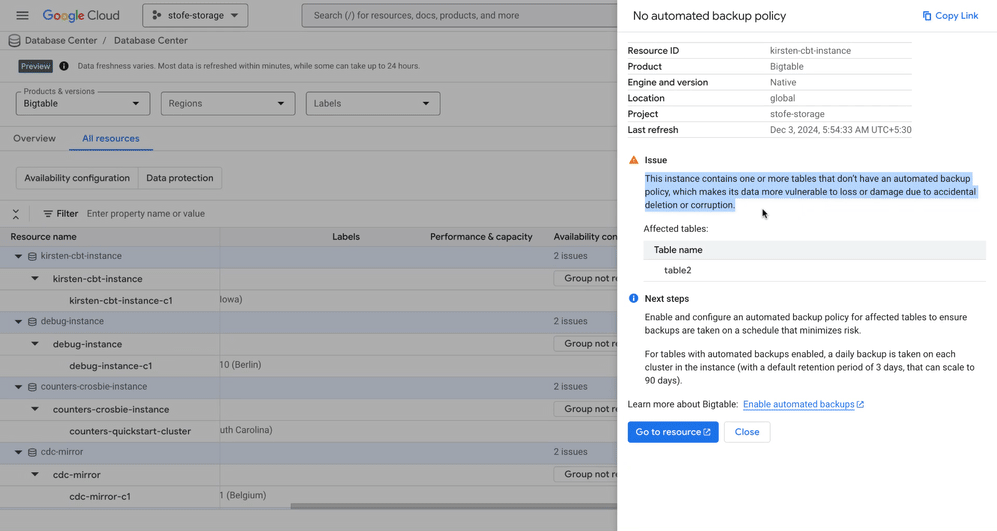
Publishes recommendations related to any unsuccessful backup attempts, no automated back-up policies and short back-up retention for your Bigtable instances. It’s important to address these issues quickly to ensure data can be recovered.
Enhances data availability and durability by protecting against system failures and regional outages for your Bigtable instances.
Helps safeguard your critical data in Firestore by detecting if any tables lack an automated backup policy, so you can prevent data loss from accidents or corruption
In short, when issues arise, Database Center guides you through intuitive troubleshooting steps, streamlining resolution and minimizing downtime for your Bigtable and Firestore deployments. It goes beyond problem identification to provide clear, actionable solutions. Recommendations for Memorystore are coming to Database Center soon along with additional recommendations for other engines!
Detecting and troubleshooting diverse database issues across the entire fleet.
Optimize your database fleet with AI-powered assistance
With Gemini enabled, Database Center makes optimizing your database fleet incredibly intuitive. Chat with the AI-powered interface to get precise answers, uncover issues within your database fleet, troubleshoot problems, and implement solutions. AI-powered chat in the Database Center now includes support for Bigtable, Memorystore and Firestore. For example, Gemini can help you quickly identify Firestoreresources that do not have automated back-up policies.
A natural language Interface to ask questions about Bigtable, Memorystore and Firestore databases.
Get started with Database Center today
With today’s launch, Database Center now provides you a single, unified view across all your Google Cloud managed databases. You can access the Database Center within the Google Cloud console and begin monitoring and managing your entire database fleet. To learn more about Database Center’s capabilities, check out the documentation.
Spanner is Google’s always-on, virtually unlimited database that powers planet-scale applications like Gmail, YouTube, and Google Photos. Outside of Google, Spanner powers demanding workloads for household brands like Yahoo!, The Home Depot, Wayfair, and Pokémon Go. Today, Spanner handles over 4 billion queries per second at peak and more than 15 exabytes of data, with five 9s of availability, plus global consistency.
Since we first discussed it in 2012, Spanner has evolved from a groundbreaking distributed SQL database into a versatile, intelligent innovation platform. 2024 was a big year for Spanner, with multiple launches that expanded its functional capabilities, pushed the envelope on price-performance, re-architected it for best-in-class reliability and security, and enhanced the developer experience. Here is a recap of Spanner’s biggest innovations of the year and how you can benefit from them.
aside_block
<ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud databases’), (‘body’, <wagtail.rich_text.RichText object at 0x3e22bceecb50>), (‘btn_text’, ‘Start building for free’), (‘href’, ‘http://console.cloud.google.com/freetrial?redirectPath=/products?#databases’), (‘image’, None)])]>
1. Multi-model — one database, many possibilities
With the launch of Spanner Graph, full-text search and vector search, Spanner went from being a highly available, globally consistent and scalable database, to a multi-model database with intelligent, interoperable capabilities with which you can build AI-enabled applications. Unlike other multi-model databases on the market, Spanner offers a true multi-model experience that allows interoperability between different data models without downtime.
Spanner’s multi-model support lets you consolidate databases, saving on costs and reducing operational overhead, governance, and security touchpoints, while its interoperability eliminates data movement for a “true ZeroETL” experience with consistent data across all models. This helps enable use cases like near-real-time fraud detection, supply chain optimization, or product recommendations.
Fig1: A SQL query on Spanner showing interleaved usage of graph, relational, and vector models and full-text search
2. Improving price-performance
Spanner’s price-performance lets you dream big, start small (for as little as $65/mo), and scale linearly with no cliffs. In 2022, we increased the storage per node from 2T to 4T, and in 2023 we built on this with a 50% increase in throughput and a 2.5X increase in storage at no additional cost.
This year, with the launch of new multi-model capabilities, we wanted to make it simple and cost effective for you to use these capabilities without charging incrementally for every new feature. The result was Spanner editions, an intuitive, tier-based pricing approach that offers different capabilities at various price points to fit you diverse needs and budgets, all while providing flexibility, cost transparency and additional cost saving opportunities.
3. A new home for your Cassandra workloads
The Cassandra NoSQL database is prized for its speed and scalability. It also has limitations, such as limited support for complex queries and difficulty modeling intricate relationships. Spanner combines the scalability and availability of NoSQL with the strong consistency and relational model of traditional databases, for the best of both worlds.
This year, we launched the Cassandra to Spanner Proxy Adapter, an open-source, plug-and-play tool that makes it easier than ever to move your Cassandra workload to Spanner with near-zero changes to your application logic. Customers like Yahoo! and Reltio are loving the ease of use of the Cassandra proxy adapter, and we’re excited to help customers be more successful with Cassandra on Spanner.
4. Generative AI and the Spanner ecosystem
Over the past year, we’ve witnessed a remarkable shift in how organizations leverage generative AI. But gen AI comes with risk of hallucinations. We believe thattransactional and analytical databases can help reduce these,bridging the gap between foundation models and enterprise gen AI apps. Here’s how:
Vector support: With vector support for Spanner, developers can perform similarity searches on vector embeddings stored in the database. Spanner vector search supports both exact KNN and approximate ANN searches, providing flexibilit for different workloads that leverage Google’s scalable nearest neighbor (ScaNN) algorithm, providing fast and accurate results, even on large datasets. Spanner now supports vector searches scaling to more than 10 billion vectors. Developers can combine vector searches with regular SQL and graph GQL queries to power use-cases like RAG applications.
BigQuery and Spanner better together: New, groundbreaking integrations between Spanner and BigQuery help businesses connect operational and analytical workloads, to unlock valuable insights and drive better decision-making. Spanner external datasets in BigQueryallows you to query transactional data residing in Spanner directly within BigQuery, without needing to move or duplicate data. Spanner now also supports reverse ETL from BigQuery to export data from BigQuery to Spanner, so you can operationalize the analytical insights that BigQuery enables.
5. Reliability, availability, security, and governance
Spanner customers expect the highest levels of reliability, availability, security, and governance controls for their mission-critical workloads. This year, we launched support for dual-region configurations and geo-partitioning to help you improve your availability SLAs, improve application performance for multi-region workloads, and meet governance requirements.
Dual-region support: Spanner dual-region configurations help meet local residency requirements while providing five 9s of availability and zero recovery-point objective (RPO) guarantees in geographies with only two regions.
Geo-partitioning: You can partition your table data at the row-level across the globe, to serve data closer to your users. With geo-partitioning, Spanner customers across industries like gaming, e-commerce, and financial services can provide theirusers reduced application latency, optimized costs, and data residency benefits such as storing sensitive user data within geographic jurisdictions.
At Google Cloud, we strive to make it ridiculously simple to build and manage applications built on our databases, including Spanner.
Protobuf improvements:Protocol Buffers, or protobuf, is a language-neutral way to encode and decode data structures for efficient transport and storage. You can now manage protobuf values in Spanner and access their fieldsusing the dot operator in SQL, e.g., dimensions.size.width, without having to normalize into tables upfront. This dramatically simplifies writing queries that need to filter, group, or order by specific values within a protobuf.
Troubleshooting and Database Center support: Database Center is an AI-powered unified database management solution to monitor and manage diverse database services. This year, customers started to be able to use Database Center to manage their Spanner databases. We also added support for end-to-end tracing and client tracing to make it easier to troubleshoot performance issues.
We are proud of what we have delivered for customers in 2024, and are excited to see the innovative solutions you are building on Spanner. Needless to say, we are just getting started and we have a lot more exciting capabilities lined up for 2025.
Get started
Want to learn more about what makes Spanner unique and how it’s being used today? Try it yourself for free for 90-days or for as little as $65 USD/month for a production-ready instance that grows with your business without downtime or disruptive re-architecture.
If you’re a regular reader of this blog, you know that 2024 was a busy year for Google Cloud. From AI to Zero Trust, and everything in between, here’s a chronological recap of our top blogs of 2024, according to readership. You’ll probably see some favorites on this list, and discover a few that you missed the first time around.
January
We started the new year strong, removing data transfer fees for anyone moving data off of our platform. Translation: Anyone doing cool things on Google Cloud (like using generative AI to analyze their microservices deployment) is doing it because they want to, not because they have to. And in business news, we shared how to make the most out of your data and AI in the coming year.
From local GPUs, to model libraries, to distributed system design, the second month of 2024 was the first of many to come where AI topics dominated the charts. Our Transform team explored gen AI’s impact on various industries.
If it wasn’t already obvious, this month’s top-read blogs showed that our core audience is developers pushing the boundaries of innovation. Business leaders, meanwhile, read about best practices for securely deploying AI on Google Cloud.
Watch out, here comes Google Cloud Next, where we made a record 218 announcements; the top three are listed here. Readers were also keen to hear about how Citadel Securities built out a research platform on Google Cloud.
We don’t always get it right, but when there’s a problem, we’re committed to providing you with accurate, timely information with which to make your own assessments. We’re also committed to making you, and customers like McLaren Racing, go really, really fast when developing new AI-based applications.
Whether you wanted to modernize your databases, deliver higher system reliability, create really cool AI-powered apps, or learn how legendary companies tackle data management, the Google Cloud blog was your go-to source midway through the year.
We talk a lot about “meeting customers where they are.” Sometimes that means a disaster zone, a remote research station, or a truck cruising down the highway. Over on Transform, you read about the history of our custom Axion and TPU chips.
Just when you thought you knew how to run AI inference, your available graph database options, or the name of Google Cloud’s event-driven programming service, we went and changed things up. We like to keep you on your toes 😉 And business readers got a first look at AI agents — more to come on this.
You’ve been generating (and storing) business data for years. Now, we’re making it easier for you to make sense of, and actually use, that data. Speaking of using data, the Transform team compiled a jaw-dropping list of the real-world ways customers are using gen AI in their organizations.
According to this month’s most-read blog, 75% of you rely on AI for at least one daily professional responsibility, including code writing, information summarization, and code explanation, and experience “moderate” to “extreme” productivity gains. So it was no big surprise that business leaders wanted to read about how to develop an AI strategy.
Not content to hold the existing record for most nodes in a Kubernetes cluster (15,000), we went ahead and more than quadrupled it, to the delight of AI unicorns. But whether you work for an AI unicorn, or just a plain old zebra, all Google Cloud users needs to start using multi-factor authentication next year, as well as learn how to avoid comman AI pitfalls.
We’re closing out the year on an AI highnote, with the availability of amazing new image and video generation models, as well as the new Trillium TPU, which Google used to train Gemini 2.0, our most capable AI model… yet. Be on the lookout for how these technologies — and many others — will reshape your industry and how you work in the coming year.
Today, AWS Backup announces additional options to assign resources to a backup policy on AWS Organizations in the AWS GovCloud (US) Regions. Customers can now select specific resources by resource type and exclude them based on resource type or tag. They can also use the combination of multiple tags within the same resource selection.
With additional options to select resources, customers can implement flexible backup strategies across their organizations by combining multiple resource types and/or tags. They can also exclude resources they do not want to back up using resource type or tag, optimizing cost on non-critical resources.
To get started, use your AWS Organizations’ management account to create or edit an AWS Backup policy in the AWS GovCloud (US) Regions. Then, create or modify a resource selection using the AWS Organizations’ API, CLI, or JSON editor in either the AWS Organizations or AWS Backup console. For more information, visit our documentation and launch blog.
Amazon Q in Connect now supports 64 languages for agent assistance capabilities. Customer service agents can now chat with Q for assistance in their native language and Q will provide answers, knowledge article links, and recommended step-by-step guides in said language. New languages supported include: Chinese, French, French (Canadian), Italian, Japanese, Korean, Malay, Portuguese, Spanish, Swedish, and Tagalog.
Stability AI’s Stable Diffusion 3.5 Large (SD3.5 Large) is now available in Amazon Bedrock. SD3.5 Large is an advanced text-to-image model featuring 8.1 billion parameters. Trained on Amazon SageMaker HyperPod, this powerful model will enable AWS customers to generate high-quality, 1-megapixel images from text descriptions with superior accuracy and creative control.
The model excels at creating diverse, high-quality images across multiple styles, making it valuable for media, gaming, advertising, ecommerce, corporate training, retail, and education industries. Its enhanced capabilities include exceptional photorealism with detailed 3D imagery, superior handling of multiple subjects in complex scenes, and improved human anatomy rendering. The model also generates representative images with diverse skin tones and features without requiring extensive prompting. Today, Stable Image Ultra in Amazon Bedrock has been updated to include Stable Diffusion 3.5 Large in the model’s underlying architecture.
AWS Partner Central Analytics now provides insights for resell revenue for AWS Partners participating in the AWS Solution Provider or Distribution Programs. The new data helps Partners gain visibility into amortized revenue generated through resellers. With this new resell revenue section in Partner Central Analytics, Partners can measure revenue by month, reseller, end customer, and geography to help define sales growth strategies.
Prior to this launch, Partners could see discounts for authorized resell services, but received limited visibility into program revenue. With this launch, the “Solution provider and distributor“ tab within Partner Central Analytics is renamed to ”Channel“, delivering four new visualizations, providing Partners with a view into amortized resell revenue by program revenue and net program revenue. Key new features include amortized Partner revenue tracking to measure customer impact, monthly refresh schedule to include previous month’s data, and comprehensive coverage of resell revenue on authorized services. This update gives Partners customer level insights, helping Partners understand spending patterns across different regions. This helps Partners decide where and how to invest to expand their market reach. Also, these new insights help Partners better track revenue generated before and after program discounts.
Approved users of an AWS Partner organization at either the Validated or Differentiated stage can access the new datasets through the Analytics tab in AWS Partner Central.
To learn more about resell revenue available in the analytics dashboard, log in to AWS Partner Central and explore the Analytics and Insights User Guide
Amazon AppStream 2.0 extends native client support to macOS. Users can now access AppStream 2.0 streamed applications through a web browser, the AppStream 2.0 client for Windows, or AppStream 2.0 client for macOS. This additional macOS support provides more flexibility and platform options for users needing access to streamed applications and desktops.
The AppStream 2.0 client for macOS is an application you install on your Mac to access AppStream streaming sessions. The client provides enhanced capabilities and user experience. It supports two monitors with 4K resolution, and the ability to connect up to four monitors, leveraging multi-monitor layouts. Users can use keyboard shortcuts and relative mouse mode for a more natural feel.
Using macOS client you can also stream over UDP which offers a more responsive streaming quality in sub-optimal network conditions, with higher round trip latency. Additionally, to assist with troubleshooting macOS client issues, you can enable client automatic logging.
The macOS client works with Windows, Red Hat Enterprise Linux, Rocky Linux 8 based AppStream 2.0 applications and fleets. To run the AppStream 2.0 macOS client, ensure that your Mac is running macOS 13 (Ventura), macOS 14 (Sonoma), or macOS 15 (Sequoia).
To download and install the AppStream 2.0 macOS client application, visit Amazon AppStream 2.0 Downloads, choose the macOS link, download and install the application. Verify that the Amazon AppStream 2.0 client application icon appears on your Mac Launchpad and start streaming.
AWS Config now supports 3 additional AWS resource types. This expansion provides greater coverage over your AWS environment, enabling you to more effectively discover, assess, audit, and remediate an even broader range of resources.
With this launch, if you have enabled recording for all resource types, then AWS Config will automatically track these new additions. The newly supported resource types are also available across the AWS Config feature set, including Config rules, Config aggregators, and Config advanced queries.
You can now use AWS Config to monitor the following newly supported resource types in all AWS Regions where the supported services are available:
AWS::Cognito::IdentityPool
AWS::MediaConnect::Gateway
AWS::OpenSearchServerless::VpcEndpoint
To view the complete list of AWS Config supported resource types, see supported resource types page.
Amazon Elastic Container Services (Amazon ECS) now allows you to perform network fault injection experiments on your applications deployed on AWS Fargate. Fault injection experiments create disruptions to test how your applications behave, helping you improve application performance, observability, and resilience. AWS Fault Injection Service (AWS FIS) now supports 6 actions for ECS on both EC2 and Fargate: network latency, network blackhole, network packet loss, CPU stress, I/O stress, and kill process.
Developers and operators can now verify the response of their application to potential network errors, some of which may also be required for regulatory compliance. By reproducing network behaviors that may cause applications to fail, you can identify gaps in application configurations, monitoring, alarms, and operational response. Amazon ECS is introducing the ability to opt-in to allow tasks to use a fault injector such as AWS FIS to perform network experiments for increasing network latency, increasing packet loss, and blackhole port testing (dropping inbound or outbound traffic) to test how your applications perform, in addition to existing resource stress experiments.
Amazon AppStream 2.0 now offers support for Rocky Linux from CIQ, enabling ISVs and central IT organizations to stream from an RPM Package Manager (RPM) compatible environment optimized for running compute-intensive applications while leveraging the flexibility, scalability, and cost-effectiveness of the AWS Cloud. With this launch, customers have the flexibility to choose from a broader set of operating systems including Rocky Linux, Red Hat Enterprise Linux (RHEL), and Microsoft Windows.
This launch enables organizations to stream Rocky Linux apps from AppStream 2.0, helping to accelerate time to market, scaling resources up or down with demand, and managing the entire fleet centrally through the AWS Management Console. Rocky Linux on AppStream 2.0 also enables traditional desktop apps to be converted to SaaS delivery without the cost of refactoring, while pay-as-you-go billing and license-included images ensure you only pay for the resources you use.
Rocky Linux-based AppStream 2.0 instances are supported in all AWS Regions where AppStream 2.0 is available and use per second billing (with a minimum of 15 minutes). For more information, see Amazon AppStream 2.0 pricing.
Meta’s Llama 3.3 70B model is now available in Amazon Bedrock. Llama 3.3 70B represents a significant advancement in model efficiency and performance optimization. This instruction-tuned model delivers impressive capabilities across diverse tasks, including multilingual dialogue, text summarization, and complex reasoning. Llama 3.3 70B is a text-only instruction-tuned model that provides enhanced performance relative to Llama 3.1 70B–and to Llama 3.2 90B when used for text-only applications.
The new model delivers similar performance to Llama 3.1 405B, while requiring only a fraction of the computational resources. Llama 3.3 demonstrates substantial improvements in reasoning, mathematical understanding, general knowledge, and instruction following. Its comprehensive training enables robust language understanding across multiple domains. You can use Llama 3.3 for enterprise applications, content creation, and advanced research initiatives. The model supports multiple languages and outperforms many existing conversational models on industry standard benchmarks. It also supports the ability to leverage model outputs to improve other models including synthetic data generation and distillation. Llama 3.3 provides an accessible and powerful generative AI solution for businesses seeking high-quality, efficient language model capabilities.
Meta’s Llama 3.3 70B model is available in Amazon Bedrock in the US East (Ohio) Region, and in the US East (N. Virginia) and US West (Oregon) Regions via cross-region inference. To learn more, visit the Llama product page and documentation. To get started with Llama 3.3 70B in Amazon Bedrock, visit the Amazon Bedrock console.
Amazon Connect now supports multi-party chat, allowing up to 4 additional agents to join an ongoing chat conversation, making it easier to collaborate and resolve customer issues quickly. For example, agents can add a supervisor or subject matter experts to join the chat, ensuring customers receive accurate and timely support.
Multi-party chat can be enabled within the AWS Console. Once enabled, agents can simply use a Quick Connect to invite additional agents to an ongoing chat. This feature is available in all commercial AWS regions where Amazon Connect is available. To learn more and get started, please refer to the help documentation or visit the Amazon Connect website.