 for open data interoperability")
GCP – Iceberg REST Catalog now supported in BigLake metastore (GA) for open data interoperability
Today, many organizations are moving towards lakehouse architectures to have a single copy of their data and use multiple engines for different workloads — without having to copy or move the data. However, managing a data lakehouse can be complex, often requiring custom pipelines that are hard to operate and that aren’t interoperable between query engines. Further, governance can be challenging when you have independent systems in multiple, local silos.
One way to succeed with a lakehouse architecture is to implement a metadata layer across your data engines. BigLake metastore is Google Cloud’s fully-managed, serverless, and scalable runtime metastore based on the industry-standard Apache Iceberg REST Spec, providing a standard REST interface for wider compatibility and interoperability across OSS engines like Apache Spark, as well as Google Cloud native engines such as BigQuery. Today, we’re excited to announce that support for the Iceberg REST Catalog is now generally available.
Now your users can query using their engine of choice across open-source engines such as Apache Spark and Trino, as well as native engines like BigQuery, all backed with the enterprise security offered by Google Cloud. For example, Spark users can utilize the BigLake metastore as a serverless Iceberg catalog to share the same copy of data with other engines, including BigQuery.
BigLake metastore also provides support for key authorization mechanisms such as credential vending, allowing users to access their tables without having direct access to the files in the underlying Google Cloud Storage bucket. Finally, BigLake metastore is integrated with Dataplex Universal Catalog so you get end-to-end governance complete with comprehensive lineage, data quality, and discoverability capabilities for BigLake Iceberg tables in BigQuery. Powered by Google’s planet-scale metadata management infrastructure based on Spanner, BigLake metastore removes the need to manage custom metastore deployments, giving you the benefits of an open and flexible lakehouse with the performance and interoperability of an enterprise-grade managed service.
Leading organizations building their lakehouses with Google’s Data Cloud are already seeing the benefits of BigLake metastore.
“Spotify is leveraging BigLake and BigLake metastore as part of our efforts to build a modern lakehouse platform. By utilizing open formats and open APIs, this platform provides an interoperable and abstracted storage interface for our data. BigLake helps us make our data accessible for processing by BigQuery, Dataflow and open-source, Iceberg-compatible engines.” – Ed Byne, Product Manager, Spotify
Simplify data management and unify governance
BigLake metastore has a new UX console in which you can create and update your Iceberg Catalog. For easy access, the console lets you access all your Cloud Storage and BigQuery storage data across multiple runtimes, including BigQuery, and open-source, Iceberg-compatible engines such as Spark and Trino. For example, a data engineer can create Iceberg tables in Spark and the same data can be accessed by a data analyst in BigQuery. This gives you a single view of all of your Iceberg tables across Google Cloud, whether they’re managed by BigLake or self-managed in Cloud Storage.
Get started using the Iceberg REST catalog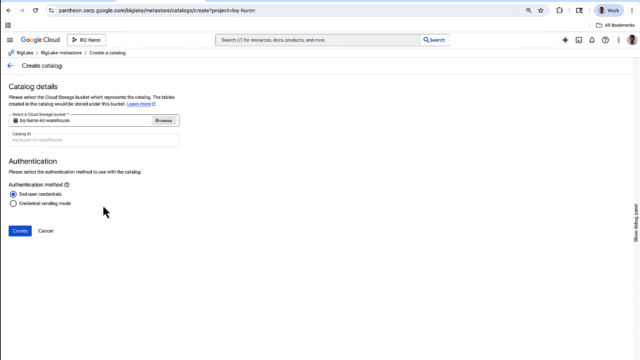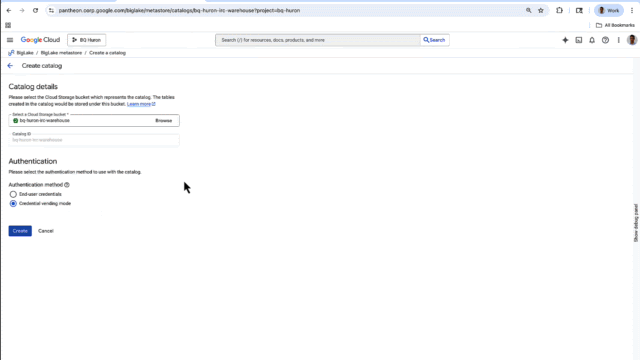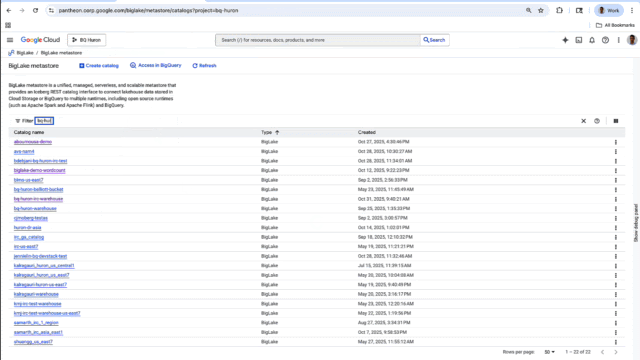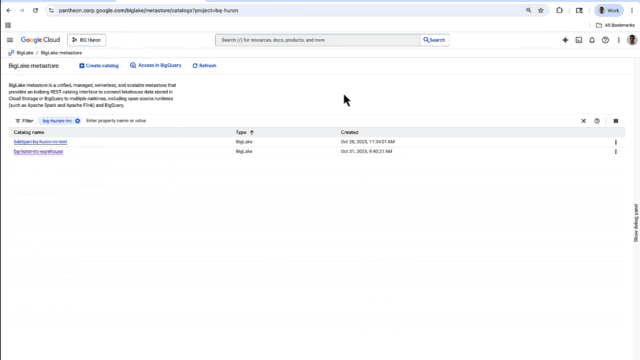
The BigLake UX console also lets you quickly create a catalog for your Iceberg data in Cloud Storage, rather than having to do it from the source.

With BigLake metastore, you can enjoy the following benefits:
- Unified metadata: Shared runtime metadata across various engines, data formats and modalities, so you can understand and process the same underlying data without needing proprietary connectors or data copies. This enables data engineers to share the same data across multiple engines, leading to faster time to market for their key use cases.
- Open APIs for interoperability: Supports interoperability with open-source and third-party engines through Iceberg REST Catalog, so different teams can use their preferred analytics tools on a single, unified dataset.
- Broad storage support: Integrated access and processing with data stored in Cloud Storage or BigQuery, helping you maximize data utility and maintain flexible storage without moving or copying data.
- Serverless: Reduced TCO due to serverless and no-ops environments and scalability for any workload size.
- Enterprise readiness and scale: Backed by Google’s planet-scale infrastructure and Spanner, so your metadata can scale with your data. There’s also support for Cloud Storage Dual Region and Multi-Region buckets for data and catalog redundancy.
- AI-powered governance: End-to-end governance complete with comprehensive lineage, data quality, and discoverability capabilities for BigLake Iceberg tables in BigQuery, and integrated with Dataplex Universal Catalog.
Unlock new AI use cases with your data lakehouse
Google’s Data Cloud is built on Google’s vast infrastructure and powered by AI, offering a unified platform for AI-ready data. This allows you to build open lakehouse architectures designed to handle both structured and multimodal data, so you can unlock new AI use cases. With BigLake and BigLake metastore, you can enable richer AI processing on your Iceberg data using BigQuery AI functions for text generation, text or unstructured data analysis, and translation. These functions access Gemini and partner LLM models available from Vertex AI, Cloud AI APIs, or built-in BigQuery models. Further, you can train, evaluate, and run ML models like linear regression, k-means clustering, or time-series forecasts directly on your Iceberg data using BigQuery ML.
Let’s take an example. Imagine you’re a data engineer at a large retail company, and a data analyst wants to access a product returns table to view a list of returned products. Some of the returns data is inserted into an Iceberg table by a data scientist on the Marketing team using Spark. Spark uses BigLake metastore Iceberg REST Catalog as the Catalog for the Iceberg table. Then, with the help of the Iceberg REST Catalog, the data scientist can immediately analyze the returns data, using BigQuery to list the returned products, BigQuery’s AI Generate function to describe the products, and BigQuery ML to plot a logistic regression model for the returns. The whole process is fast thanks to the use of the Cloud Storage FileIO implementation (GCSFileIO), while Dataplex Universal Catalog provides governance capabilities for BigLake Iceberg tables in BigQuery.
Learn more
With BigLake metastore, you now have a fully-managed, serverless, and scalable runtime metastore, enabling an open and interoperable lakehouse for your organization. Get started with BigLake metastore and the Iceberg REST Catalog today. And to learn how to build an AI-ready lakehouse with Apache Iceberg and BigLake, watch our most recent lakehouse webinar on demand where we dive deeper into the topic.
Read More for the details.

