

GCP – How Lightricks trains video diffusion models at scale with JAX on TPU
Training large video diffusion models at scale isn’t just computationally expensive — it can become impossible when your framework can’t keep pace with your ambitions.
JAX has become a popular computational framework across AI applications, now recognized for its capabilities in training large-scale AI models, such as LLMs and life sciences models. Its strength lies not just in performance but in an expressive, scalable design that gives innovators the tools to push the boundaries of what’s possible. We’re consistently inspired by how researchers and engineers leverage JAX’s ecosystem to solve unique, domain-specific challenges — including applications for generative media.
Today, we’re excited to share the story of Lightricks, a company at the forefront of the creator economy. Their LTX-Video team is building high-performance video generation models, and their journey is a masterclass in overcoming technical hurdles. I recently spoke with Yoav HaCohen and Yaki Bitterman, who lead the video and scaling teams, respectively. They shared their experience of hitting a hard scaling wall with their previous framework and how a strategic migration to JAX became the key to unlocking the performance they needed.
Here, Yoav and Yaki tell their story in their own words. – Srikanth Kilaru, Senior Product Manager, Google ML Frameworks
The creator’s challenge
At Lightricks, our goal has always been to bring advanced creative technology to consumers. With apps like Facetune, we saw the power of putting sophisticated editing tools directly into people’s hands. When generative AI emerged, we knew it would fundamentally change content creation.
We launched LTX Studio to build generative video tools that truly serve the creative process. Many existing models felt like a “prompt and pray” experience, offering little control and long rendering times that stifled creativity. We needed to build our own models—ones that were not only efficient but also gave creators the controllability they deserve.
Our initial success came from training our first real-time video generation model on Google Cloud TPUs with PyTorch/XLA. But as our ambitions grew, so did the complexity. When we started developing our 13-billion-parameter model, we hit a wall.
Hitting the wall and making the switch
Our existing stack wasn’t delivering the training step times and scalability we needed. After exploring optimization options, we decided to shift our approach. We paused development to rewrite our entire training codebase in JAX, and the results were immediate. Switching to JAX felt like a magic trick, instantly providing the necessary runtimes.
This transition enabled us to effectively scale our tokens per sample (the amount of data processed in each training step), model parameters, and chip count. With JAX, sharding strategies (sharding divides large models across multiple chips) that previously failed now work out of the box on both small and large pods (clusters of TPU chips).
These changes delivered linear scaling that translates to 40% more training steps per day — directly accelerating model development and time to market. Critical issues with FlashAttention and data loading also worked reliably. As a result, our team’s productivity skyrocketed, doubling the number of pull requests we could merge in a week.
Why JAX worked: A complete ecosystem for scale
The success wasn’t just about raw speed; it was about the entire JAX stack, which provided the building blocks for scalable and efficient research.
-
A clear performance target with MaxText: We used the open-source MaxText framework as a baseline to understand what acceptable performance looked like for a large model on TPUs. This gave us a clear destination and the confidence that our performance goals were achievable on the platform.
-
A robust toolset: We built our new stack on the core components of the JAX ecosystem based on the MaxText blueprint. We used Flax for defining our models, Optax for implementing optimizers, and Orbax for robust checkpointing — all core components that work together natively.
-
Productive development and testing: The transition was remarkably smooth. We implemented unit tests to compare our new JAX implementation with the old one, ensuring correctness every step of the way. A huge productivity win was discovering that we could test our sharding logic on a single, cheap CPU before deploying to a large TPU slice. This allowed for rapid, cost-effective iteration.
-
Checkpointing reliability: For sharded models, JAX’s checkpointing is much more reliable than before, making training safer and more cost-effective.
-
Compile speed & memory: JAX compilation with lax.fori_loop is fast and uses less memory, freeing capacity for tokens and gradients.
- Smooth scaling on a supercomputer: With our new JAX codebase, we were able to effectively train on a reservation of thousands of TPU cores. We chose TPUs because Google provides access to what we see as a “supercomputer” — a fully integrated system where the interconnects and networking were designed first, not as an afterthought. We manage these large-scale training jobs with our own custom Python scripts on Google Compute Engine (GCE), giving us direct control over our infrastructure. We also use Google Cloud Storage and stream the training data to the TPU virtual machines.
Architectural diagram showing the Lightricks stack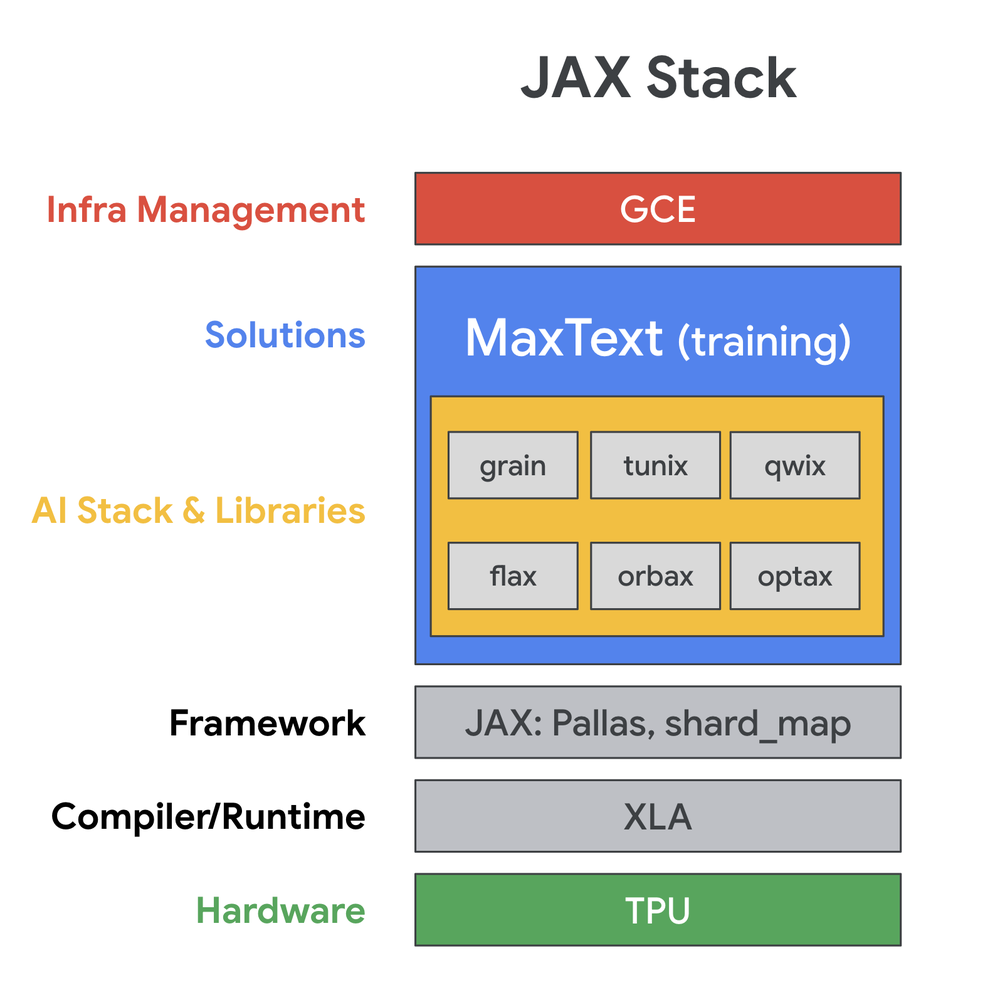
Build your models with the JAX ecosystem
Lightricks’ story is a great example of how JAX’s powerful, modular, and scalable design can help teams overcome critical engineering hurdles. Their ability to quickly pivot, rebuild their stack, and achieve massive performance gains is a testament to both their talented team and the tools at their disposal.
The JAX team at Google is committed to supporting innovators like Lightricks and the entire scientific computing community.
-
Share your story: Are you using JAX to tackle a challenging scientific problem? We would love to learn how JAX is accelerating your research.
-
Help guide our roadmap: Are there new features or capabilities that would unlock your next breakthrough? Your feature requests are essential for guiding the evolution of JAX.
Please reach out to the team via GitHub to share your work or discuss what you need from JAX. Check out documentation, examples, news, events and more at jaxstack.ai and jax.dev.
Sincere thanks to Yoav, Yaki, and the entire Lightricks team for sharing their insightful journey with us. We’re excited to see what they create next.
Read More for the details.

