
GCP – How Model Armor can help protect your AI apps from prompt injections and jailbreaks
As AI continues to rapidly develop, it’s crucial that IT teams address the business and organizational risks posed by two common threats: prompt injection and jailbreaking.
Earlier this year we introduced Model Armor, a model-agnostic advanced screening solution that can help safeguard gen AI prompts and responses, and agent interactions. Model Armor offers a comprehensive suite of integration options, including direct API integration for developers, and inline integrations with Apigee, Vertex AI, Agentspace, and network service extensions.
Many organizations already rely on Apigee as an API gateway, using capabilities such as Spike Arrest, Quota, and OAuth 2.0 for traffic and security management. By integrating with Model Armor, Apigee can become a critical security layer for generative AI interactions.
This powerful combination allows for proactive screening of prompts and responses, ensuring AI applications are secure, compliant, and operate within defined guardrails. Today, we’re explaining how to get started using Model Armor with Apigee to secure your AI apps.
How to use Model Armor for AI app protection
Model Armor has five main capabilities.
-
Prompt injection and jailbreak detection: It identifies and blocks attempts to manipulate an LLM into ignoring its instructions and safety filters.
-
Sensitive data protection: It can detect, classify, and prevent the exposure of sensitive information, including personally identifiable information (PII) and confidential data in both user prompts and LLM responses.
-
Malicious URL detection: It scans for malicious and phishing links in both the input and output to prevent users from being directed to harmful websites, and to stop the LLM from inadvertently generating dangerous links.
-
Harmful content filtering: It has built-in filters to detect content that is sexually explicit, dangerous, and contains harassment or hate speech, ensuring that outputs align with responsible AI principles.
-
Document screening: It can also screen text in documents, including PDFs and Microsoft Office files, for malicious and sensitive content.
Model Armor integration with Apigee and LLMs.
Model Armor is designed to be model-independent and cloud-agnostic, meaning it can help to secure any gen AI model via REST APIs, regardless of whether it’s running on Google Cloud, another cloud provider, or a different platform. It exposes a REST endpoint or inline integration with other Google AI and networking services to perform these functions.
How to get started
-
In the Google Cloud console, enable the Model Armor API and click on “Create a template.”
-
Enable prompt injection and jailbreak detection. You can also enable the other safety filters as shown above, and click “Create.”
-
Create a service account (or update an existing service account that has been used to deploy Apigee proxies,) and enable permissions in Model Armor User (roles/modelarmor.user) and Model Armor Viewer (roles/modelarmor.viewer) on the service account.
-
From the Apigee console, create a new Proxy and enable the Model Armor policies.
-
If you already have a proxy for the LLM calls, add two Apigee policies in the flow: SanitizeUserPrompt and SanitizeModelResponse.
-
In the policy details, update reference to the Model Armor template created earlier. For example, projects/some-test-project/locations/us-central-1/templates/safeguard_llms. Similarly, configure the <SanitizeModelResponse> policy.
-
Provide the source of the user prompt in the request payload Eg: JSON path.
-
Configure the LLM endpoint as the target backend of Apigee Proxy and deploy the proxy by using the Service account configured above. Your proxy should now be working and interacting with the Model Armor and LLM endpoints.
-
During proxy execution, when Apigee invokes the Model armor, it returns a response that includes the “filter execution state” and “match state”. Apigee populates several flow variables with information from the Model Armor response like
SanitizeUserPrompt.POLICY_NAME.piAndJailbreakFilterResult.executionState and SanitizeUserPrompt.POLICY_NAME.piAndJailbreakFilterResult.matchState -
You can use a <Condition> to check if this flow variable equals MATCH_FOUND and configure the <RaiseFault> policy within your proxy’s flow.
Steps to configure Model Armor and integrate with Apigee to protect AI applications.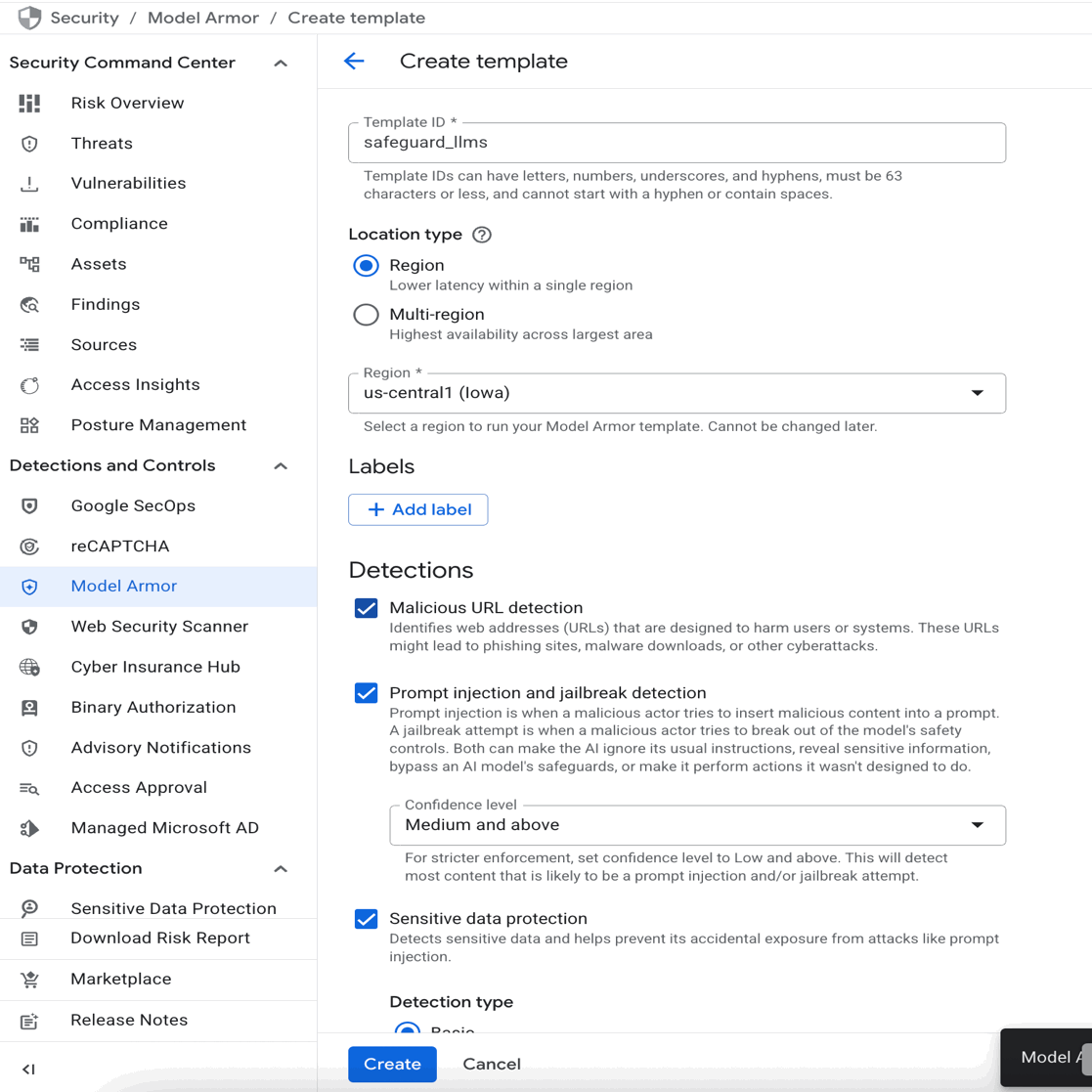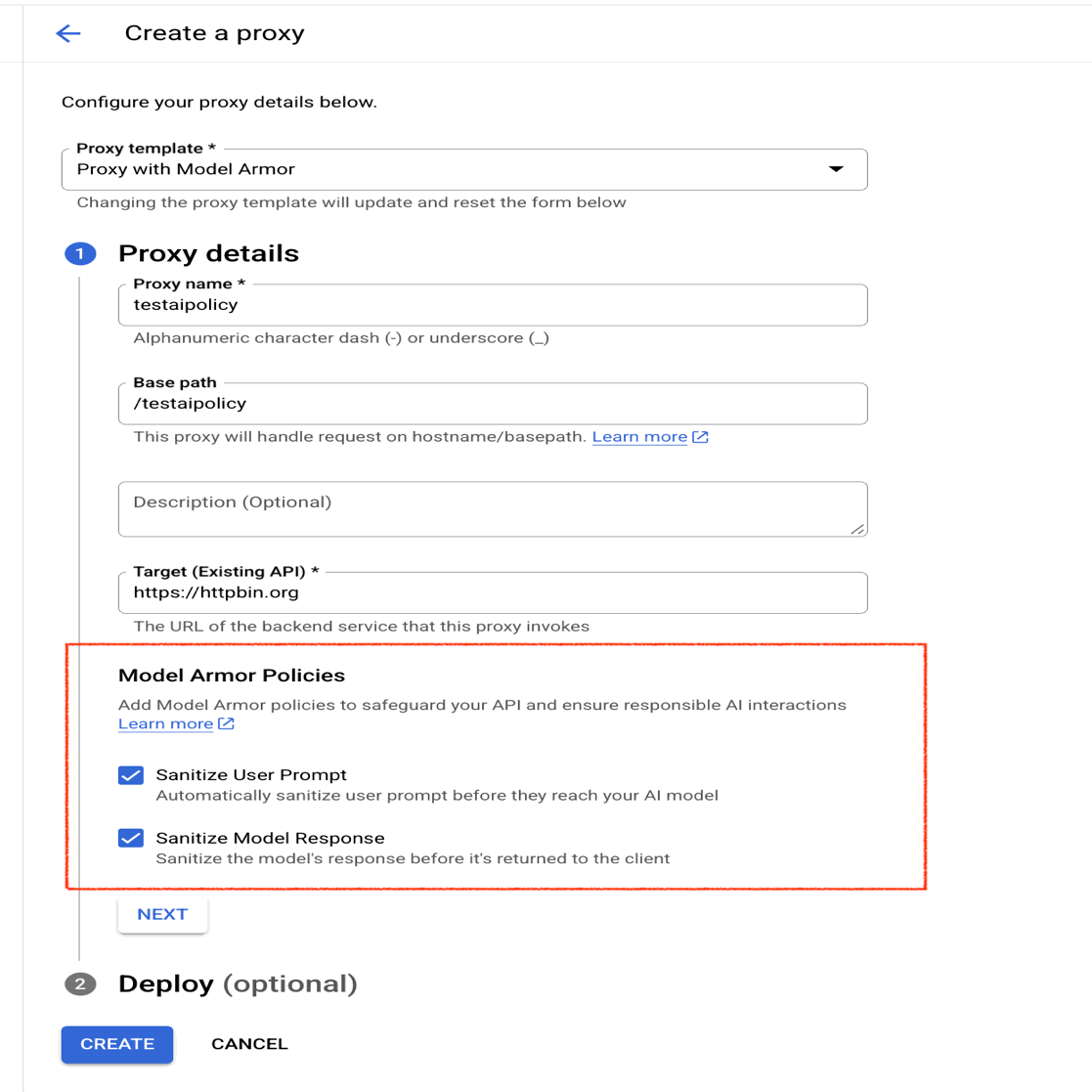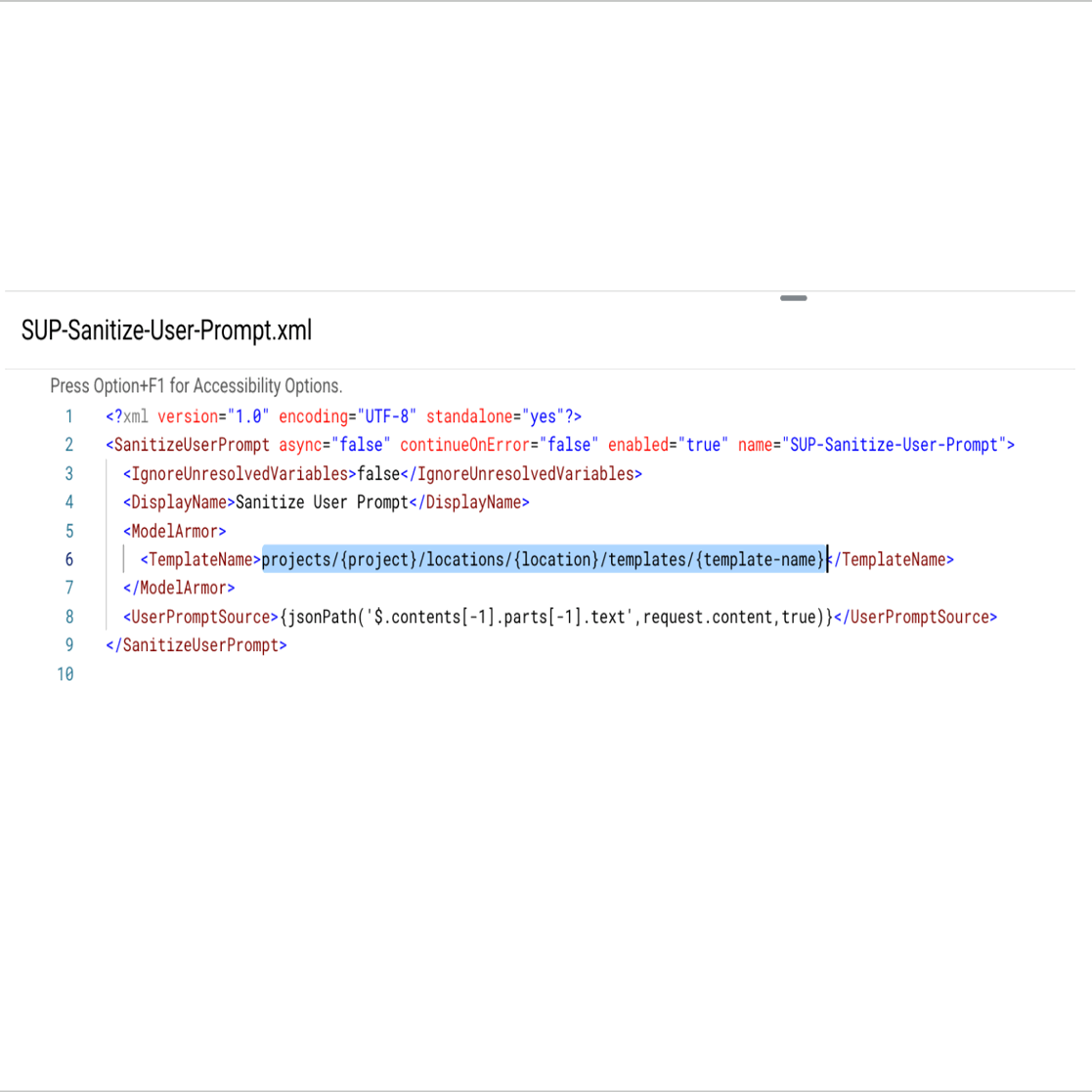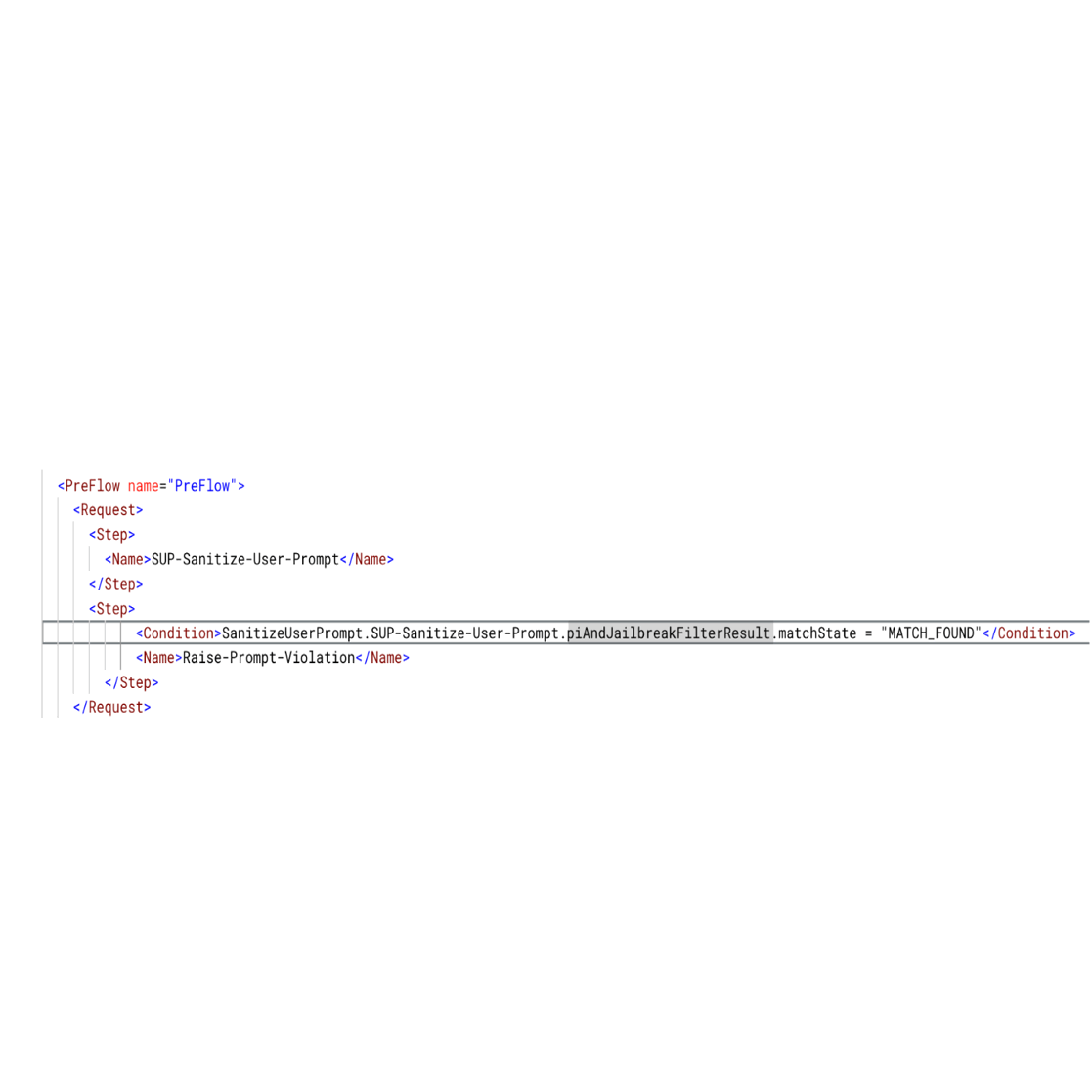
Review the findings
You can view the Model Armor findings in the AI Protection dashboard on the Security Command Center. A graph presents the volume of prompts and responses analyzed by Model Armor, along with the count of identified issues.
It also summarizes various detected issue types, including prompt injection, jailbreak detection, and sensitive data identification.
Prompt and response content analytics provided by AI Protection dashboard.
With your knowledge of Model Armor, you’re ready to adjust the floor settings. Floor settings define the minimum security and safety requirements for all Model Armor templates in a specific part of your Google Cloud resource hierarchy. You can set confidence levels for responsible AI safety categories (such as hate speech and harassment,) prompt injection and jailbreak detection, and sensitive data protection (including topicality.)
Model Armor floor setting defines confidence levels for filtering.
Model Armor logging captures administrative activities like creating or updating templates and sanitation operations on prompts and responses, which can be viewed in Cloud Logging. You can configure logging within Model Armor templates to include details such as the prompt, response, and evaluation results.
Learn more by getting hands-on
Explore the tutorial for integrating Apigee with Model Armor here, and try the guided lab on configuring Model Armor.
Read More for the details.

