
GCP – Introducing LLM-Evalkit: A practical framework for prompt engineering on Google Cloud
If you’ve worked with Large Language Models (LLMs), you’re likely familiar with this scenario: your team’s prompts are scattered across documents, spreadsheets, and different cloud consoles. Iterating is often a manual and inefficient process, making it difficult to track which changes actually improve performance.
To address this, we’re introducing LLM-Evalkit, a light-weight, open-source application designed to bring structure to this process. LLM-Evalkit is a practical lightweight framework built on Vertex AI SDKs using Google Cloud that centralizes and streamlines prompt engineering, enabling teams to track objective metrics and iterate more effectively.
Centralizing a disparate workflow
Currently, managing prompts on Google Cloud can involve juggling several tools. A developer might experiment in one console, save prompts in a separate document, and use another service for evaluation. This fragmentation leads to duplicated effort and makes it hard to establish a standardized evaluation process. Different team members might test prompts in slightly different ways, leading to inconsistent results.
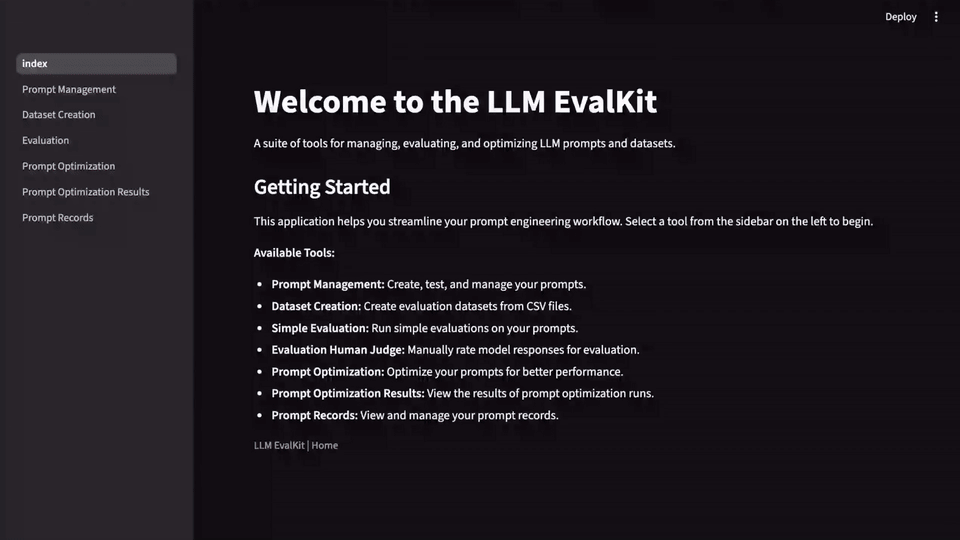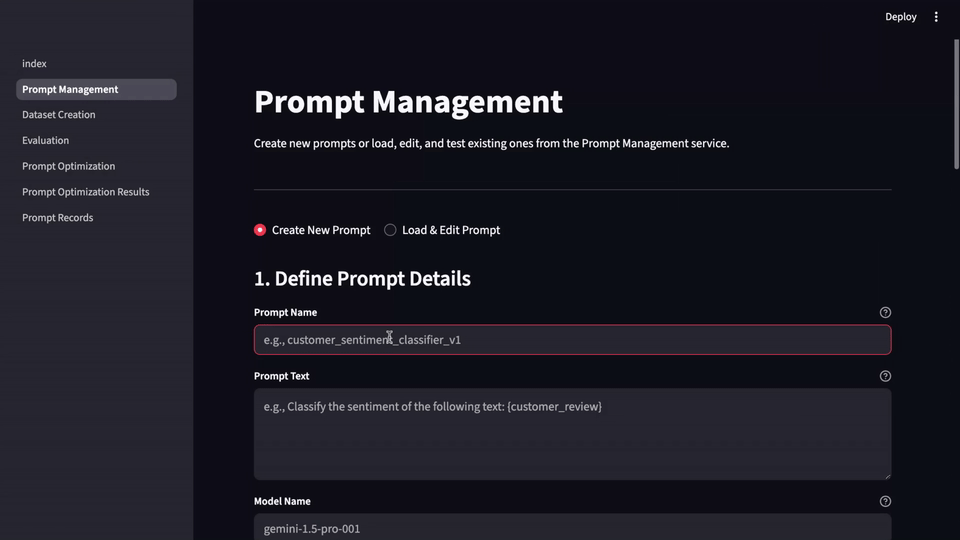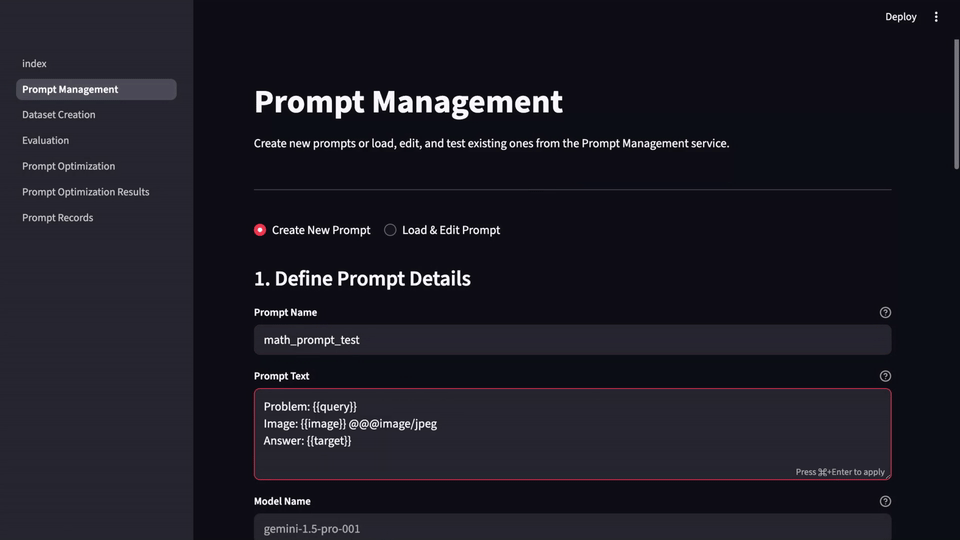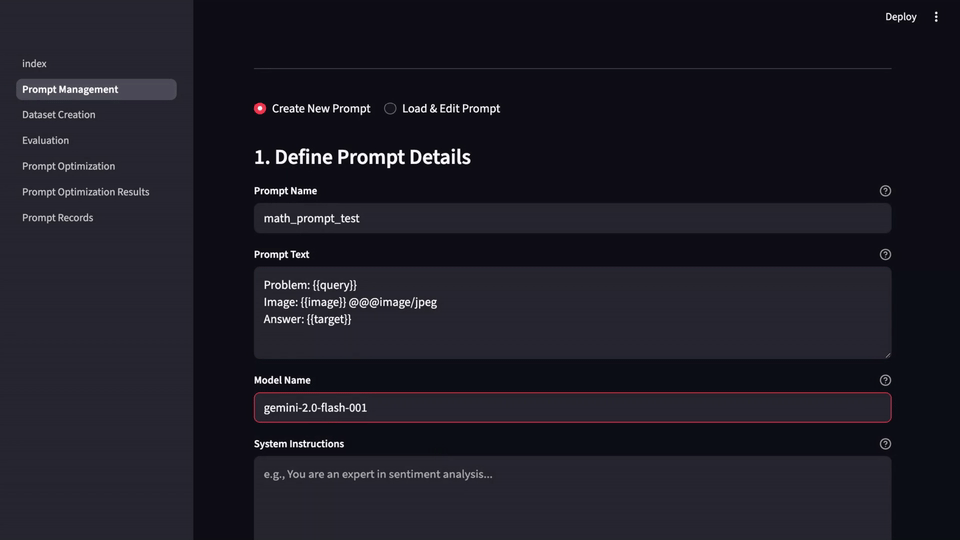
LLM-Evalkit solves this by abstracting these disparate tools into a single, cohesive application. It provides a centralized hub for all prompt-related activities, from creation and testing to versioning and benchmarking. This unification simplifies the workflow, ensuring that all team members are working from the same playbook. With a shared interface, you can easily track the history and performance of different prompts over time, creating a reliable system of record.
- aside_block
- <ListValue: [StructValue([(‘title’, ‘$300 in free credit to try Google Cloud AI and ML’), (‘body’, <wagtail.rich_text.RichText object at 0x7f82ec352b80>), (‘btn_text’, ”), (‘href’, ”), (‘image’, None)])]>
From guesswork to measurement
Too often, teams iterate on prompts based on subjective “feel” or a few example outputs. While this can work initially, it doesn’t scale and makes it difficult to justify why one prompt is truly better than another.
LLM-Evalkit encourages a shift in focus from the prompt itself to the problem you’re trying to solve. The methodology is straightforward:
-
Start with a specific problem: Clearly define the task you want the LLM to perform.
-
Gather or create a relevant dataset: Build a set of test cases that represent the kinds of inputs the model will see.
-
Build concrete measurements: Define objective metrics to score the model’s outputs against your dataset.
This approach allows for systematic, data-driven iterations. Instead of guessing whether a new prompt is an improvement, you can measure its performance against a consistent benchmark. Progress can be tracked against objective metrics, making it clear which changes lead to better, more reliable results.
Empowering teams with a no-code approach
Prompt engineering shouldn’t be limited to those who are comfortable with complex tooling and code. When only a few technical team members can effectively build and test prompts, it creates a bottleneck that slows down the development cycle.
LLM-Evalkit addresses this with a no-code, user-friendly interface. The goal is to make prompt engineering accessible to a wider range of team members, including product managers, UX writers, and subject matter experts who have valuable domain knowledge but may not be developers. By democratizing the process, teams can iterate more quickly, test a wider range of ideas, and foster better collaboration between technical and non-technical stakeholders.
Get started
LLM-Evalkit is designed to bring a more systematic and collaborative approach to prompt engineering. By providing a centralized, metric-driven, and no-code framework, it helps teams move from ad-hoc experimentation to a more structured and efficient workflow.
We encourage you to try it out. You can find the open-source repository and documentation on our GitHub. We look forward to seeing how your teams use it to build more effectively with LLMs. For the most up-to-date evaluation features, you can explore them directly in the Google Cloud console. If you prefer a guided approach, a specific console tutorial is available to walk you through the process, providing you with flexible options for all your prompt engineering needs.
Read More for the details.

