

GCP – Pirates in the Data Sea: AI Enhancing Your Adversarial Emulation
Matthijs Gielen, Jay Christiansen
Background
New solutions, old problems. Artificial intelligence (AI) and large language models (LLMs) are here to signal a new day in the cybersecurity world, but what does that mean for us—the attackers and defenders—and our battle to improve security through all the noise?
Data is everywhere. For most organizations, the access to security data is no longer the primary issue. Rather, it is the vast quantities of it, the noise in it, and the disjointed and spread-out nature of it. Understanding and making sense of it—THAT is the real challenge.
When we conduct adversarial emulation (red team) engagements, making sense of all the network, user, and domain data available to us is how we find the path forward. From a defensive perspective, efficiently finding the sharpest and most dangerous needles in the haystack—for example, easily accessible credentials on fileshares—is how we prioritize, improve, and defend.
How do you make sense of this vast amount of structured and unstructured data, and give yourself the advantage?
Data permeates the modern organization. This data can be challenging to parse, process, and understand from a security implication perspective, but AI might just change all that.
This blog post will focus on a number of case studies where we obtained data during our complex adversarial emulation engagements with our global clients, and how we innovated using AI and LLM systems to process this into structured data that could be used to better defend organizations. We will showcase the lessons learned and key takeaways for all organizations and highlight other problems that can be solved with this approach for both red and blue teams.
Approach
Data parsing and understanding is one of the biggest early benefits of AI. We have seen many situations where AI can help process data at a fast rate. Throughout this post, we use an LLM to process unstructured data, meaning that the data did not have a structure or format that we knew about before parsing the data.
If you want to try these examples out yourself, please make sure you use either a local model, or you have permission to send the data to an external service.
Getting Structured Data Out of an LLM
Step one is to get the data into a format we can use. If you ever used an LLM, you will have noticed it will output as a story or prose text, especially if you use chat-based versions. For a lot of use cases, this is fine; however, we want to analyze the data and get structured data. Thus, the first problem we have to solve is to get the LLM to output the data in a format we can specify. The simple method is to ask the LLM to output the data in a machine readable format like JSON, XML, or CSV. However, you will quickly notice that you have to be quite specific with the data format, and the LLM can easily output data in another format, ignoring your instructions.
Luckily for us, other people have encountered this problem and have solved it with something called Guardrails. One of the projects we have found is called guardrails-ai. It is a Python library that allows you to create guardrails—specific requirements—for a model based on Pydantic.
To illustrate, take a simple Python class from the documentation to validate a pet from the output of the LLM:
from pydantic import BaseModel, Field
class Pet(BaseModel):
pet_type: str = Field(description="Species of pet")
name: str = Field(description="a unique pet name")You can use the next code from the Guardrails documentation to process the output of the LLM into a structured object:
from guardrails import Guard
import openai
prompt = """
What kind of pet should I get and what should I name it?
${gr.complete_json_suffix_v2}
"""
guard = Guard.from_pydantic(output_class=Pet, prompt=prompt)
raw_output, validated_output, *rest = guard(
llm_api=openai.completions.create,
engine="gpt-3.5-turbo-instruct"
)
print(validated_output)If we look at what this library generates underwater for this prompt, we see that it adds a structured object part with the instructions for the LLM to output data in a specific way. This streamlines the way you can get structured data from an LLM.
Figure 1: The generated prompt from the Pydantic model
For the next use case, we will show the Pydantic models we’ve created to process the output.
Red Team Use Cases
The next sections contain some use cases where we can use an LLM to get structured data out of data obtained. The use cases are divided into three categories of the attack lifecycle:
-
Initial Reconnaissance
-
Escalate Privileges
-
Internal Reconnaissance
Figure 2: Attack lifecycle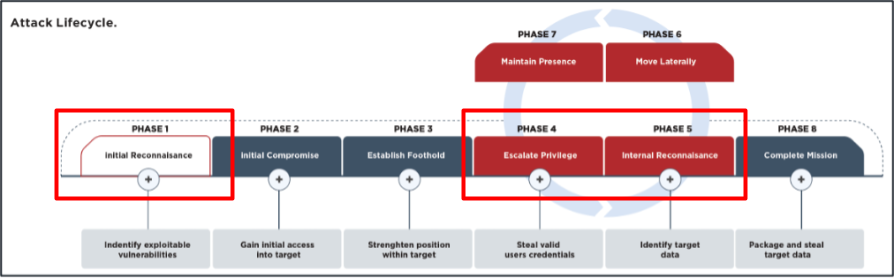
Initial Reconnaissance
Open Source Intelligence (OSINT) is an important part of red teaming. It includes gathering data about the target organization from news articles, social media, and corporate reports.
This information can then be used in other red team phases such as during phishing. For defenders, it helps them understand which parts of their organization are exposed to the internet, anticipating a possible future attack. In the next use case, we talk about processing social media information to process roles and extract useful information.
Use Case 1: Social Media Job Functions Information
During OSINT, we often try to get information from employees about their function in their company. This helps with performing phishing attacks, as we do not want to target IT professionals, especially those that work in cybersecurity.
Social media sites allow their users to write about their job titles in a free format. This means that the information is unstructured and can be written in any language and any format.
We can try to extract the information from the title with simple matches; however, because the users can fill in anything and in any language, this problem can be better solved with an LLM.
Data Model
First, we create a Pydantic model for the Guardrail:
class RoleOutput(BaseModel):
role: str = Field(description="Role being analyzed")
it: bool = Field(description="The role is related to IT")
cybersecurity: bool = Field(description="The role is related to
CyberSecurity")
experience_level: str = Field(
description="Experience level of the role.",
)This model has two Boolean options if the role is IT or cybersecurity related. Additionally, we would like to know the experience level of the role.
Prompt
Next, let’s create a prompt to instruct the LLM to extract the requested information from the role. This prompt is quite simple and just asks the LLM to fill in the data.
Given the following role, answer the following questions.
If the answer doesn't exist in the role, enter ``.
${role}
${gr.complete_xml_suffix_v2}The two last lines are placeholders used by guardrails-ai.
Results
To test the models, we have scraped the titles that employees use on social media. This dataset contained the titles that the employees used and contained 235 entries. For testing, we used the gemini-1.0-pro model.
Gemini managed to parse 232 entries. The results are shown in Table 1.
|
Not IT |
IT |
Cybersecurity |
|
|
Gemini |
183 |
49 |
5 |
|
Manual evaluation |
185 |
47 |
5 |
|
False positive |
1 |
3 |
0 |
Table 1: Results of Gemini parsing 232 job title entries
In the end, Gemini processed the roles quite on par with a human. Most of the false positives were questionable because it is not very clear if the role was actually IT related. The experience level did not perform well, as the model deemed the experience level as “unknown” or “none” for most of the entries. To resolve this issue, the field was changed so that the experience level should be a number from 1 to 10. After running the analysis again, this yielded better results for the experience level. The lowest experience levels (1–4) contained function titles like “intern,” “specialist,” or “assistant.” This usually indicated that the person had been employed at that role for a shorter period of time. The updated data model is shown as follows:
class RoleOutput(BaseModel):
role: str = Field(description="Role being analyzed")
it: bool = Field(description="The role is related to IT")
cybersecurity: bool = Field(description="The role is related to
CyberSecurity")
experience_level: int = Field(
description="Estimate of the experience level of the role on
a scale of 1-10. Where 1 is low experience and 10 is high.",
)This approach helped us to sort through a large dataset of phishing targets by identifying employees that did not have IT and cybersecurity roles, and sorting them by experience level. This can speed up target selection for large organizations and may allow us to better emulate attackers by changing the prompts or selection criteria. To defend against this, data analysis is more difficult. In theory, you can instruct all your employees to include “Cybersecurity” in their role, but that does not scale well or solve the underlying phishing problem. The best approach with regards to phishing is, in our experience, to invest into phishing resistant multifactor authentication (MFA) and application allowlisting. If applied well, these solutions can mitigate phishing attacks as an initial access vector.
Escalate Privileges
Once attackers establish a foothold into an organization, one of their first acts is often to improve their level of access or control through privilege escalation. There are quite a few methods that can be used for this. It comes in a local system-based variety as well as wider domain-wide types, with some based on exploits or misconfigurations, and others based on finding sensitive information when searching through files.
Our focus will be on the final aspect, which aligns with our challenge of identifying the desired information within the vast amount of data, like finding a needle in a haystack.
Use Case 2: Credentials in Files
After gaining initial access to the target network, one of the more common enumeration methods employed by attackers is to perform share enumeration and try to locate interesting files. There are quite a few tools that can do this, such as Snaffler.
After you identify files that potentially contain credentials, you can go through them manually to find useful ones. However, if you do this in a large organization, there is a chance that you will have hundreds to thousands of hits. In that case, there are some tools that can help with finding and classifying credentials like TruffleHog and Nosey Parker. Additionally, the Python library detect-secrets can help with this task.
Most of these tools look for common patterns or file types that they understand. To cover unknown file types or credentials in emails or other formats, it might instead be valuable to use an LLM to analyze the files to find any unknown or unrecognized formats.
Technically, we can just run all tools and use a linear regression model to combine the results into one. An anonymized example of a file with a password that we encountered during our tests is shown as follows:
@Echo Off
Net Use /Del * /Yes
Set /p Path=<"path.txt"
Net Use %Path% Welcome01@ /User:CHAOS.LOCALWorkstationAdmin
If Not Exist "C:Data" MKDIR "C:Data"
Copy %Path%. C:Data
Timeout 02Data Model
We used the following Python classes to instruct Gemini to retrieve credentials with an optional domain. One file can contain multiple credentials, so we use a list of credentials to instruct Gemini to optionally retrieve multiple credentials from one file.
class Credential(BaseModel):
password: str = Field(description="Potential password of an account")
username: str = Field(description="Potential username of an account")
domain: Optional[str] = Field(
description="Optional domain of an account", default=""
)
class ListOfCredentials(BaseModel):
credentials: list[Credential] = []Prompt
In the prompt, we give some examples of what kind of systems we are looking for, and output into JSON once again:
Given the following file, check if there are credentials in the file.
Only include results if there is at least one username and password.
If the domain doesn't exist in the file, enter `` as a default value.
${file}
${gr.complete_xml_suffix_v2}Results
We tested on 600 files, where 304 contain credentials and 296 do not. Testing occurred with the gemini-1.5 model. Each file took about five seconds to process.
To compare results with other tools, we also tested Nosey Parker and TruffleHog. Both NoseyParker and Truffle Hog are made to find credentials in a structured way in files, including repositories. Their use case is usually for known file formats and randomly structured files.
The results are summarized in Table 2.
|
Tool |
True Negative |
False Positive |
False Negative |
True Positive |
|
Nosey Parker |
284 (47%) |
12 (2%) |
136 (23%) |
168 (28%) |
|
TruffleHog |
294 (49%) |
2 (<1%) |
180 (30%) |
124 (21%) |
|
Gemini |
278 (46%) |
18 (3%) |
23 (4%) |
281 (47%) |
Table 2: Results of testing for credentials in files, where 304 contain them and 296 do not
In this context, the definitions of true negative, false positive, false negative, and true positive are as follows:
-
True Negative: A file does not contain any credentials, and the tool correctly indicates that there are no credentials.
-
False Positive: The tool incorrectly indicates that a file contains credentials when it does not.
-
False Negative: The tool incorrectly indicates that a file does not contain any credentials when it does.
-
True Positive: The tool correctly indicates that a file contains credentials.
In conclusion, Gemini finds the most files with credentials, at a cost of a slightly higher false positive rate. TruffleHog has the lowest false positive rate, but also finds the least amount of true positives. This is to be expected, as a higher true positive rate usually is accompanied by a higher false positive rate. The current dataset has almost an equal number of files with and without credentials—in real-world scenarios this ratio can differ wildly, which means that the false positive rate is still important even though the percentages are quite close.
To optimize this approach, you can use all three tools, combine the output signals to a single signal, and then sort the potential files based on this combined signal.
Defenders can, and should, use the same techniques previously described to enumerate the internal file shares and remove or limit access to files that contain credentials. Make sure to check what file shares each server and workstation exposes to the network, because in some cases file shares are exposed accidentally or were forgotten about.
Internal Reconnaissance
When attackers have gained a better position in the network, the next step in their playbooks is understanding the domain in which they have landed so they can construct a path to their ultimate goal. This could be full domain control or access to specific systems or users, depending on the threat actor’s mission. From a red team perspective, we need to be able to emulate this. From a defender’s perspective, we need to find these paths before the attackers exploit them.
The main tool that red teamers use to analyze Active Directory is BloodHound, which uses a graph database to find paths in the Active Directory. BloodHound is executed in two steps. First, an ingester retrieves the data from the target Active Directory. Second, this data is ingested and analyzed by BloodHound to find attack paths.
Some tools that can gather data to be used in BloodHound are:
-
Sharphound
-
Bloodhound.py
-
Rusthound
-
Adexplorer
-
Bofhound
-
Soaphound
These tools gather data from the Active Directory and other systems and output it in a format that BloodHound can read. In theory, if we have all the information about the network in the graph, then we can just query the graph to figure out how to achieve our objective.
To improve the data in BloodHound, we have thought of additional use cases. Use Case 3 is about finding high-value systems. Discovering more hidden edges in BloodHound is part of Use Case 4 and Use Case 5.
Use Case 3: High-Value Target Detection in Active Directory
By default, BloodHound deems some groups and computers as high value. One of the main activities in internal reconnaissance is figuring out which systems in the client’s network are high-value targets. Some examples of systems that we are interested in, and that can lead to domain compromise, are:
-
Backup systems
-
SCCM
-
Certificate services
-
Exchange
-
WSUS systems
There are many ways to indicate which servers are used for a certain function, and it depends on how the IT administrators have configured it in their domain. There are some fields that may contain data in various forms to indicate what the system is used for. This is a prime example of unstructured data that might be analyzable with an LLM.
The following fields in the Active Directory might contain the relevant information:
-
Name
-
Samaccountname
-
Description
-
Distinguishedname
-
SPNs
Data Model
In the end, we would like to have a list of names of the systems the LLM has deemed high value. During development, we noticed that LLM results improved dramatically if you asked it to specify a reason. Thus, our Pydantic model looks like this:
class HighValueSystem(BaseModel):
name: str = Field(description="Name of this system")
reason: str = Field(description="Reason why this system is
high value", default="")
class HighValueResults(BaseModel):
systems: list[HighValueSystem] = Field(description="high value
systems", default=[])Prompt
In the prompt, we give some examples of what kind of systems we are looking for:
Given the data, identify which systems are high value targets,
look for: sccm servers, jump systems, certificate systems, backup
systems and other valuable systems. Use the first (name) field to
identify the systems.Results
We tested this prompt on a dataset of 400 systems and executed it five times. All systems were sent in one query to the model. To accommodate this, we used the gemini-1.5 model because it has a huge context window. Here are some examples of reasons Gemini provided, and what we think the reason was based off:
-
Domain controller: Looks like this was based on the “OU=Domain Controllers” distinguishedname field of BloodHound
-
Jumpbox: Based on the “OU=Jumpboxes,OU=Bastion Servers” distinguishedname
-
Lansweeper: Based on the description field of the computer
-
Backup Server: Based on “OU=Backup Servers” distinguishedname
Some of the high-value targets are valid yet already known, like domain controllers. Others are good finds, like the jumpbox and backup servers. This method can process system names in other languages and more verbose descriptions of systems to determine systems that may be high value. Additionally, this method can be adapted to allow for a more specific query—for example, that might suit a different client environment:
Given the data, identify which systems are related to
SWIFT. Use the first (name) field to identify the systems.In this case, the LLM will look for SWIFT servers and may save you some time searching for it manually. This approach can potentially be even better when you combine this data with internal documentation to give you results, even if the Active Directory information is lacking any information about the usage of the system.
For defenders, there are some ways to deal with this situation:
-
Limit the amount of information in the Active Directory and put the system descriptions in your documentation instead of within the Active Directory
-
Limit the amount of information a regular user can retrieve from the Active Directory
-
Monitor LDAP queries to see if a large amount of data is being retrieved from LDAP
Use Case 4: User Clustering
After gaining an initial strong position, and understanding the systems in the network, attackers will often need to find the right users to compromise to gain further privileges in the domain. For defenders, legacy user accounts or administrators with too many rights is a common security issue.
Administrators often have multiple user accounts: one for normal operations like reading email and using it on their workstations, and one or multiple administrator accounts. This separation is done to make it harder for attackers to compromise the administrator account.
There are some common flaws in the implementations that sometimes make it possible to bypass these separations. Most of the methods require the attacker to cluster the users together to see which accounts belong to the same employee. In many cases, this can be done by inspecting the Active Directory objects and searching for patterns in the display name, description, or other fields. To automate this, we tried to find these patterns with Gemini.
Data Model
For this use case, we would like to have the account’s names that Gemini clusters together. During initial testing, the results were quite random. However, after adding a “reason” field, the results improved dramatically. So we used the next Pydantic model:
class User(BaseModel):
accounts: list[Account] = Field(
description="accounts that probably belongs
to this user", default=[]
)
reason: str = Field(
description="Reason why these accounts belong
to this user", default=""
)
class UserAccountResults(BaseModel):
users: list[User] = Field(description="users with multiple
accounts", default=[])Prompt
In the prompt, we give some examples of what kind of systems we are looking for:
Given the data, cluster the accounts that belong to a single person
by checking for similarities in the name, displayname and sam.
Only include results that are likely to be the same user. Only include
results when there is a user with multiple accounts. It is possible
that a user has more than two accounts. Please specify a reason
why those accounts belong to the same user. Use the first (name)
field to identify the accounts.Results
The test dataset had about 900 users. We manually determined that some users have two to four accounts with various permissions. Some of these accounts had the same pattern like “user@test.local” and “adm-user@test.local.” However, other accounts had patterns where the admin account was based on the first couple of letters. For example, their main account had the pattern matthijs.gielen@test.local, and the admin account was named: adm-magi@test.local. To keep track of those accounts, the description of the admin account contained some text similar to “admin account of Matthijs Gielen.”
With this prompt, Gemini managed to cluster 50 groups of accounts in our dataset. After manual verification, some of the results were discarded because they only contained one account in the cluster. This resulted in 43 correct clusters of accounts. Manually, we found the same correlation; however, where Gemini managed to output this information in a couple of minutes, manually this took quite a bit longer to analyze and correlate all accounts. This information was used in preparation for further attacks, as shown in the next use case.
Use Case 5: Correlation Between Users and Their Machines
Knowing which users to target or defend is often not enough. We also need to find them within the network in order to compromise them. Domain administrators are (usually) physical people; they need somewhere to type in their commands and perform administrative actions. This means that we need to correlate which domain administrator is working from which workstation. This is called session information, and BloodHound uses this information in an edge called “HasSession.”
In the past, it was possible to get all session information with a regular user during red teaming.
Using the technique in Use Case 4, we can correlate the different user accounts that one employee may have. The next step is to figure out which workstation belongs to that employee. Then we can target that workstation, and from there, hopefully recover the passwords of their administrator accounts.
In this case, employees have corporate laptops, and the company needs to keep track of which laptop belongs to which employee. Often this information is stored in one of the fields of the computer object in the Active Directory. However, there are many ways to do this, and using Gemini to parse the unstructured data is one such example.
Data Model
This model is quite simple, we just want to correlate machines to their users and have Gemini give us a reason why—to improve the output of the model. Because we will send all users and all computers at once, we will need a list of results.
class UserComputerCorrelation(BaseModel):
user: str = Field(description="name of the user")
computer: str = Field(description="name of the computer")
reason: str = Field(
description="Reason why these accounts belong to this user",
default=""
)
class CorrelationResults(BaseModel):
results: list[UserComputerCorrelation] = Field(
description="users and computers that correlate", default=[]
)Prompt
In the prompt, we give some examples of what kind of systems we are looking for:
Given the two data sets, find the computer that correlates
to a user by checking for similarities in the name, displayname
and sam. Only include results that are likely to correspond.
Please specify a reason why that user and computer correlates.
Use the first (name) field to identify the users and computers.Results
The dataset used contains around 900 users and 400 computers. During the assignment, we determined that the administrators correlated users and their machines via the description field of the computer, which was sort of equal to the display name of the user. Gemini correctly picked up this connection, correctly correlating around 120 users to their respective laptops (Figure 3).
Figure 3: Connections between user and laptop as correlated by Gemini
Gemini helped us to select an appropriate workstation, which enabled us to perform lateral movement to a workstation and obtain the password of an administrator, getting us closer to our goal.
To defend against these threats, it can be valuable to run tools like BloodHound in the network. As discussed, BloodHound might not find all the “hidden” edges in your network, but you can add these yourself to the graph. This will allow you to find more Active Directory-based attack paths that are possible in your network and mitigate these before an attacker has an opportunity to exploit those attack paths.
Conclusion
In this blog post, we looked at processing red team data using LLMs to aid in adversarial emulation or improving defenses. These use cases were related to processing human-generated, unstructured data. Table 3 summarizes the results.
|
Use Case |
Accuracy of the Results |
Usefulness |
|
Roles |
High: There were a few false positives that were in the gray area. |
High: Especially when going through a large list of roles of users, this approach will provide fairly fast results. |
|
Credentials in files |
High: Found more credentials than comparable tools. More testing should look into the false-positive rate in real scenarios. |
Medium: This approach finds a lot more results; however, processing it with Gemini is a lot slower (five seconds per file) than many other alternatives. |
|
High-value targets |
Medium: Not all results were new, nor were all high-value targets. |
Medium: Some of the results were useful; however, all of them still require manual verification. |
|
Account clustering |
High: After taking into account the clusters with one account, the other ones were well clustered. |
High: Clustering users is most of the time a tedious process to do manually. It gives fairly reliable results if you filter out the results with only one account. |
|
Computer correlation |
High: All results were correctly correlated users to their computers. |
High: This approach produces accurate results potentially providing insights into extra possible attack paths. |
Table 3: The results of our experiments of data processing with Gemini
As the results show, using an LLM like Gemini can help in converting this type of data into structured data to aid attackers and defenders. However, keep in mind that LLMs are not a silver bullet and have limitations. For example, they can sometimes produce false positives or be slow to process large amounts of data.
There are quite a few use cases we have not covered in this blog post. Some other examples where you can use this approach are:
-
Correlating user groups to administrator privileges on workstations and servers
-
Summarizing internal website content or documentation to search for target systems
-
Ingesting documentation to generate password candidates for cracking passwords
The Future
This was just an initial step that we on the Advanced Capabilities team on the Mandiant Red Team have explored so far when using LLMs for adversarial emulation and defense. For next steps, we know that the models and prompts can be improved by testing variations in the prompts, and other data sources can be investigated to see if Gemini can help analyze them. We are also looking at using linear regression models as well as clustering and pathfinding algorithms to enable cybersecurity practitioners to quickly evaluate attack paths that may exist in a network.
Read More for the details.

