
GCP – Dataproc Metastore: Fully managed Hive metastore now available for alpha testing
Google Cloud is announcing a new data lake building block for our smart analytics platform: Dataproc Metastore, a fully managed, highly available, auto-healing, open source Apache Hive metastore service that simplifies technical metadata management for customers building data lakes on Google Cloud. With Dataproc Metastore, you now have a completely serverless option for several use cases:
-
A centralized metadata repository that can be shared among various ephemeral Dataproc clusters running different open source engines, such as Apache Spark, Apache Hive, and Presto;
-
A metadata bridge between open source tables and code-free ETL/ELT with Data Fusion;
-
A unified view of your open source tables across Google Cloud, providing interoperability between cloud-native services like Dataproc and various other open source-based partner offerings on Google Cloud.
To get started with Dataproc Metastore today, join our alpha program by reaching out by email: join-dataproc-metastore-alpha@google.com.
Why Hive Metastore?
A core benefit of Dataproc is that it lets you create a fully configured, autoscaling, Hadoop and Spark cluster in around 90 seconds. This rapid creation and flexible compute platform makes it possible to treat cluster creation and job processing as a single entity. When the job completes, the cluster can terminate and you pay only for the Dataproc resources required to run your jobs. However, information about tables—the metadata—that was created during those jobs is not always something that you want to be thrown out with the cluster. You often want to keep that table information between jobs or make the metadata available to other clusters and other processing engines.
If you use open source technologies in your data lakes, you likely already use the Hive Metastore as the trusted metastore for big data processing. Hive metastore has achieved standardization as the mechanism that open source data systems use to share data structures. The below diagram demonstrates just some of the ecosystem that is already built around Hive Metastore’s capabilities.
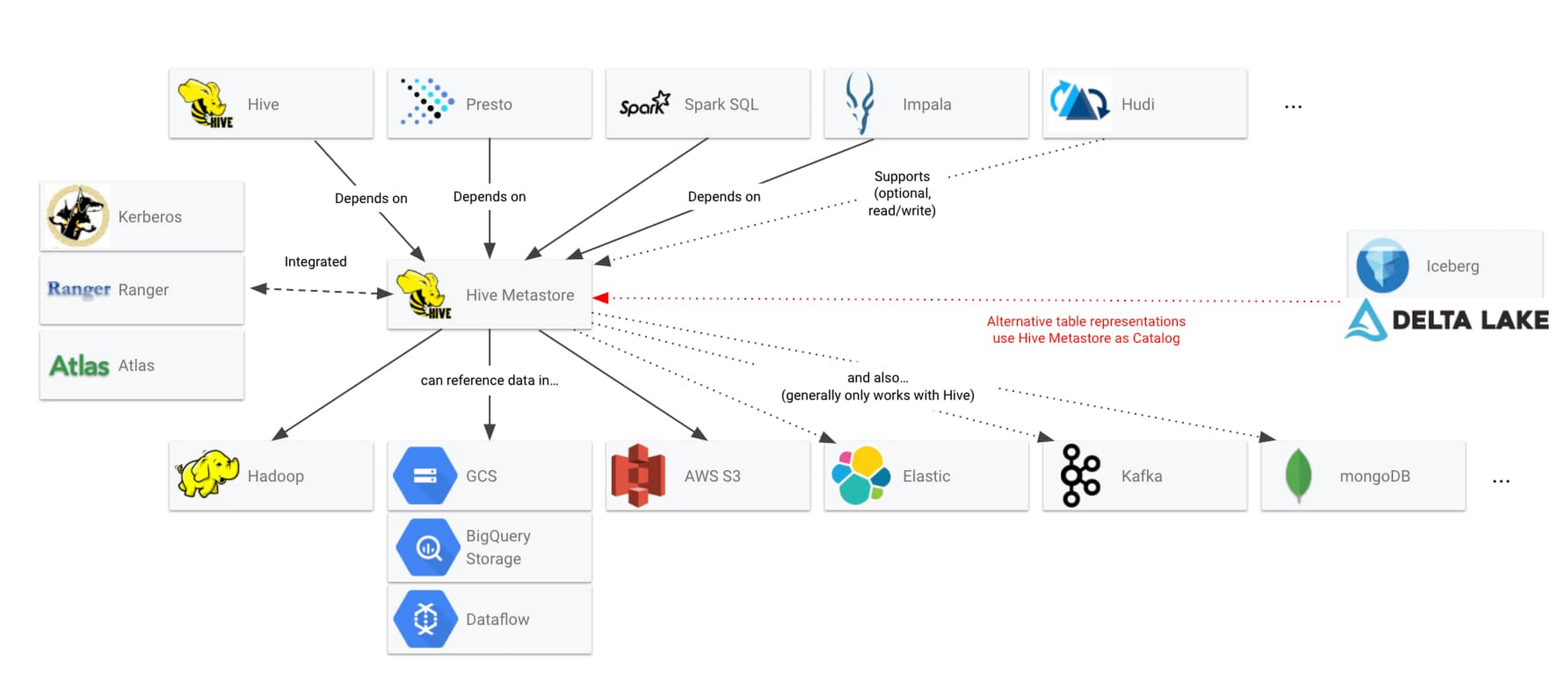
However, this same Hive Metastore can be a friction point for customers who need to run their data lakes on Google Cloud. Today, Dataproc customers will often use Cloud SQL to persist Hive metadata off-cluster. But we’ve heard about some challenges with this:
-
You must self-manage and troubleshoot the RDBMS Cloud SQL instance.
-
Hive servers are managed independently of RDBMS: This can create both scalability issues for incoming connections, and locking issues in the database.
-
The CloudSQL instance is a single point of failure that requires a maintenance window with downtime, making it impossible to use with data lakes that need always-on processing.
-
This architecture requires that direct JDBC access be provided to each cluster, which can introduce security risks when used with sensitive data.
In order to trust that the Hive Metastore can serve in the critical path for all your data processing jobs, your other option is to move beyond the CloudSQL workaround and spend significant time architecting a highly available IaaS layer that includes load balancing, autoscaling, installations and updates, testing, and backups. However, the Dataproc Metastore abstracts all of this toil and provides these as features in a managed service.
Enterprise customers have told us they want a managed Hive Metastore that they can rely on for running business-critical data workloads in Google Cloud data lakes. In addition, customers have expressed a desire for the full, open source-based Hive metastore catalog that maintains their integration points with numerous applications, can provide table statistics for query optimization, and supports Kerberos authentication so that existing security models based on tools like Apache Ranger and Apache Atlas continue to function. We also hear that customers want to avoid a new client library that would require a rewrite of existing software or a “compatible” API that only offers limited functionality of the Hive metastore. Enterprise customers want to use the full features of the open source Hive metastore.
The Dataproc Metastore team has accepted this challenge, and now provides a fully serverless Hive metastore service.
The Dataproc Metastore complements the Google Cloud Data Catalog, a fully managed and highly scalable data discovery and metadata management service. Data Catalog empowers organizations to quickly discover, understand, and manage all their data with simple and easy-to-use search interfaces, while the Dataproc Metastore offers technical metadata interoperability among open source big data processing.
Common use cases for Dataproc Metastore
Flexible analysis of your data lake with centralized metadata repository
When German wholesale giant METRO moved their ecommerce data lake to Google Cloud, they were able to match daily events to compute processing and reduce infrastructure costs by 30% to 50%. The key to these types of gains when it comes to data lakes is severing the ties between storage and compute. By disconnecting the storage layer from compute clusters, your data lake gains flexibility. Not only can clusters come up and down as needed, but cluster specifications like vCPUs, GPUs, and RAM can be tailored to the specific needs of the jobs at hand.
Dataproc already offers several features that help you achieve this flexibility.
-
Cloud Storage Connector lets you take data off your cluster by providing Cloud Storage as a Hadoop Compatible File System (HCFS). Jobs based on data in the Hadoop Distributed File System (HDFS) can typically be converted to Cloud Storage with a simple file prefix change (more on HDFS vs. Cloud Storage here).
-
Workflow Templates provides an easy-to-use mechanism for managing and executing workflows. You can specify a set of jobs to run on a managed cluster that gets created on demand and deleted when the jobs are finished.
-
Dataproc Hub makes it easy to give data scientists, analysts, and engineers preconfigured Spark working environments in JupyterLab that automatically spawn and destroy Dataproc clusters without an administrator.
Now, with Dataproc Metastore, achieving flexible clusters is even easier for those clusters that want to share tables and schemas. Clusters of various shapes, sizes, and processing engines can safely and efficiently share the same tables and metadata simply by pointing a Dataproc cluster to a serverless Dataproc Metastore endpoint, as shown here:

Serverless and code-free ETL/ELT with Dataproc Metastore and Data Fusion
We’ve heard from customers that they’re able to use real-time data to improve customer service, network optimization, and more to save time and reach customers effectively. For companies building data pipelines, they can use Data Fusion, our fully managed, code-free, and cloud-native data integration service that lets you easily ingest and integrate data from various sources. Data Fusion is built with an open source core (CDAP), which offers a Hive source plugin. With this plugin, data scientists and other users of the data lake can share the structured results of their analysis using Dataproc Metastore, offering a shared repository that ETL/ELT developers can use to manage and productionize pipelines in the data lake.
Below is one example of a workflow using Dataproc Metastore with Data Fusion to manage data pipelines, so you can go from unstructured raw data to a structured data warehouse without having to worry about running servers.
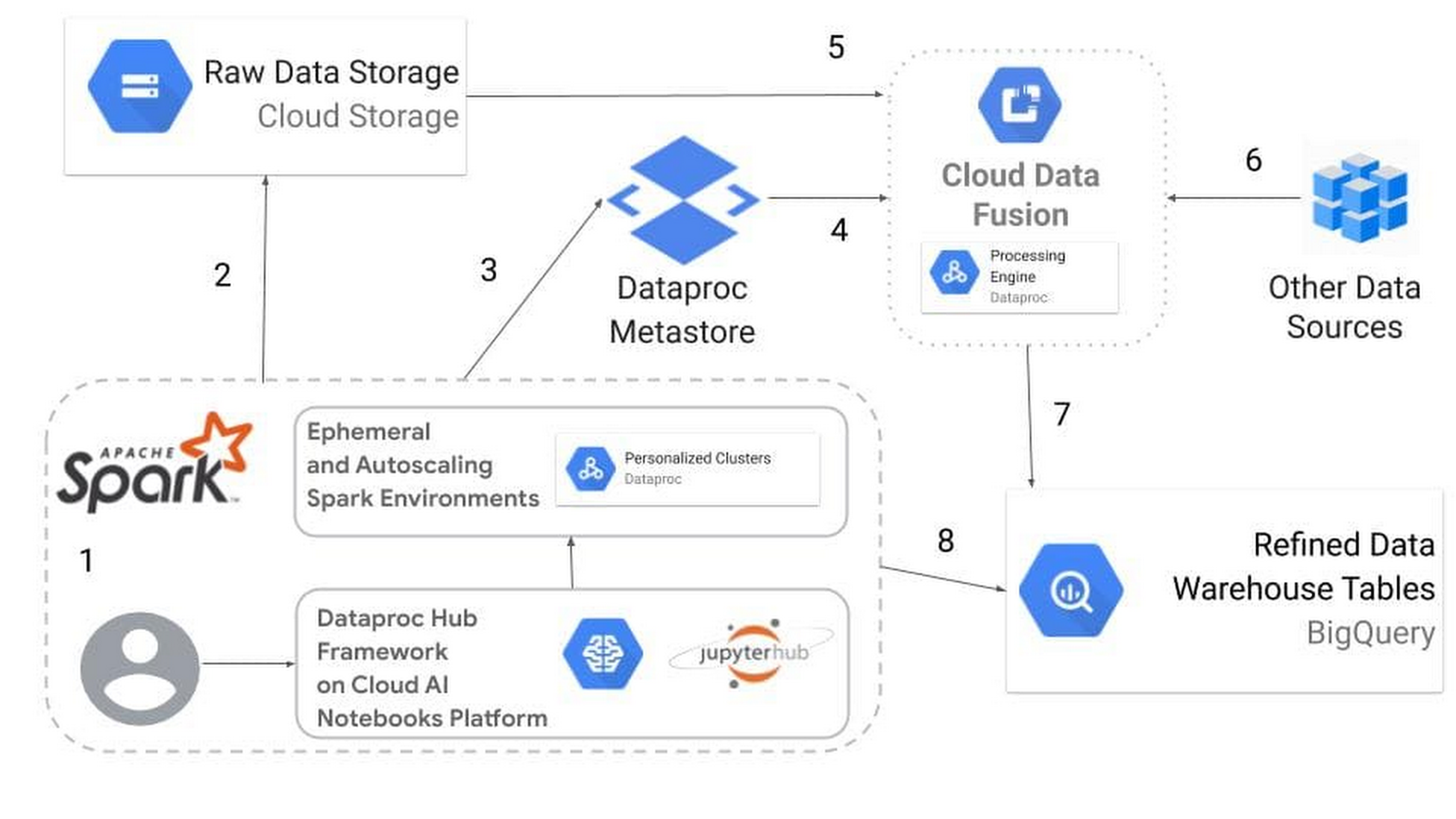
-
Data scientists, data analysts, and data engineers log in to Dataproc Hub, which they use to spawn a personalized Dataproc cluster running a Juypter lab interface backed by Apache Spark processing.
-
Unstructured raw data on Cloud Storage is analyzed, interpreted, and structured.
-
Metadata about how to interpret Cloud Storage objects as structured tables is stored in Dataproc Metastore, allowing the personalized Dataproc cluster to be terminated without losing the metadata information.
-
Data Fusion’s Hive connector uses the table created in the notebook as a data source via the thrift URL provided by Dataproc Metastore.
-
Data Fusion reads the Cloud Storage data according to the structure provided by Dataproc Metastore.
-
The data is harmonized with other data sources into a data warehouse table.
-
The refined data table is written to BigQuery, Google Cloud’s serverless data warehouse.
-
BigQuery tables are made available to Apache Spark on Jupyter Notebooks for further data lake queries and analysis with the Apache Spark BigQuery Connector.
Partner ecosystem accelerates Dataproc Metastore deployments across multi-cloud and hybrid data lakes
At Google, we believe in an open cloud, and Dataproc Metastore is built with our leading open source-centric partners in mind. Because Dataproc Metastore provides compatibility with open source Apache Hive Metastore, you can integrate Google Cloud partner services into your hybrid data lake architectures without having to give up metadata interoperability. Google Cloud-native services and open source applications can work in tandem.
Collibra provides hybrid data lake visibility with Dataproc Metastore
Integrating Dataproc Metastore with Collibra Data Catalog provides enterprises with enterprise-wide visibility across on-prem and cloud data lakes. Since Dataproc Metastore was built on top of Hive metastore, Collibra could quickly integrate into the solution without having to worry about proprietary data formats or APIs. “Dataproc Metastore provides a fully managed Hive metastore, and Collibra layers on data set discovery and governance, which is critical for any business looking to meet the strictest internal and external compliance standards,” says Chandra Papudesu, VP product management, Catalog and Lineage for Collibra.
Qubole provides a single view of metadata across data lakes
Qubole’s open data lake platform provides end-to-end data lake services, such as continuous data engineering, financial governance, analytics, and machine learning with near-zero administration on any cloud. As enterprises continue to execute a multi-cloud strategy with Qubole, it’s critical to have one centralized view of your metadata for data discovery and governance. “Qubole’s co-founders led the Apache Hive project, which has spawned into many impactful projects and contributors globally,” said Anita Thomas, director of product management at Qubole. “Qubole’s platform has used a Hive metastore since its inception, and now with Google’s launch of an open metastore service, our joint customers have multiple options to deploy a fully managed, central metadata catalog for their machine learning, ad-hoc or streaming analytics applications,”
Pricing
During the alpha phase, you will not be charged for testing this service. However, under NDA, you can be provided a tentative price list to evaluate the value of Dataproc Metastore against the proposed fees.
Sign up for the alpha testing program for Dataproc Metastore now.
Read More for the details.

